هل تساءلت يوماً كيف تعلّمت نماذج مثل ChatGPT وClaude أن تردّ بأسلوب إنساني، وأن تكون مفيدة وآمنة وصادقة في آنٍ واحد؟ الإجابة تكمن في تقنية ثورية تسمى RLHF (التعلم المعزز من ردود الفعل البشرية). قبل هذه التقنية، كانت نماذج اللغة تنتج نصوصاً متماسكة لكنها بعيدة عن ما يريده الإنسان حقاً. RLHF غيّر المعادلة كلياً، وجعل من الذكاء الاصطناعي شريكاً حقيقياً لا مجرد آلة تتنبأ بالكلمة التالية. في هذا الدليل الشامل، سنفكك هذه التقنية من الداخل — كيف تعمل، ولماذا هي جوهر أذكى نماذج 2026، وما التحديات التي تواجهها، وكيف تتطور.
جدول المحتويات
- ما هو RLHF ولماذا ظهر؟
- المراحل الثلاث لـ RLHF: من الإشراف إلى التعزيز
- نموذج المكافأة (Reward Model): القلب النابض لـ RLHF
- خوارزمية PPO: الموازنة بين الاستكشاف والاستغلال
- RLHF في الواقع: كيف دربت OpenAI نموذج ChatGPT؟
- DPO: البديل الأبسط الذي يتحدى RLHF التقليدي
- Constitutional AI وRLAIF: حين تحلّ الآلة محل المقيّم البشري
- تحديات RLHF: Reward Hacking وتحيز المقيّمين
- RLHF vs Fine-tuning vs Prompt Engineering: متى تستخدم ماذا؟
- تطبيقات RLHF في القطاعات المختلفة
- مستقبل RLHF: نحو تفضيلات ديناميكية وتعلم مستمر
- كيف تبدأ بتطبيق RLHF على نموذجك الخاص؟
- الأسئلة الشائعة
- الخلاصة
- المصادر والمراجع
ما هو RLHF ولماذا ظهر؟
مقال مرتبط: هندسة البرومبت المتقدمة 2026: الدليل الشامل من Zero-Shot إلى ReAct — هل تكتب للذكاء الاصطناعي وتحصل على نتائج مخيبة للآمال؟ في تجربتي، الفجوة بين من يحصلون على مخرجات ا…
قبل أن نفهم RLHF، علينا أن نفهم المشكلة التي جاء ليحلّها.
نماذج اللغة الكبيرة (LLMs) تُدرَّب أساساً على مهمة واحدة: التنبؤ بالكلمة التالية في جملة. هذا التدريب يمنحها معرفة واسعة باللغة، لكنه لا يُعلّمها ماذا يريد الإنسان فعلاً. النموذج قد ينتج نصاً متماسكاً لكنه غير مفيد، أو يُجيب على سؤال بطريقة تقنية صحيحة لكنها مُعقّدة لغير المتخصصين، أو في الحالات الأسوأ — ينتج محتوى ضاراً أو مضللاً.
RLHF — اختصار لـ Reinforcement Learning from Human Feedback — هو أسلوب تدريب يدمج ردود الفعل البشرية مباشرةً في حلقة التعلم. بدلاً من الاكتفاء بتعليم النموذج “ما هو صحيح لغوياً”، نعلّمه “ما يُعجب الإنسان ويناسب احتياجاته.”
وفقاً لـ AWS، فإن جوهر RLHF يقوم على تدريب نموذج مكافأة منفصل بناءً على تفضيلات بشرية، ثم استخدام هذا النموذج دالةً للمكافأة لتحسين سياسة النموذج عبر التعلم المعزز. الفكرة بسيطة لكن أثرها عميق: النموذج يتعلم أن يُعظّم ما يعتبره البشر “جواباً جيداً.”
تاريخياً، ظهر RLHF بصورة بارزة حين أطلقت OpenAI نموذج InstructGPT عام 2022، ثم ChatGPT الذي سُرعان ما أصبح الظاهرة الأوسع انتشاراً في تاريخ التكنولوجيا. الفرق بين GPT-3 العادي وChatGPT لم يكن في حجم النموذج — كان في RLHF.
مقال مرتبط: Fine-tuning vs RAG vs Prompt Engineering: الدليل الشامل 2026 — مقارنة معمّقة بين أبرز أساليب تكييف نماذج اللغة
المراحل الثلاث لـ RLHF: من الإشراف إلى التعزيز
مقال مرتبط: Function Calling في نماذج LLM: الدليل الشامل لتحويل الذكاء الاصطناعي من نصٍّ إلى فعل حقيقي (2026) — هل تساءلت يومًا كيف يستطيع ChatGPT حجز موعد أو استدعاء API أو البحث في قاعدة بيانات؟ السر يكمن في F…
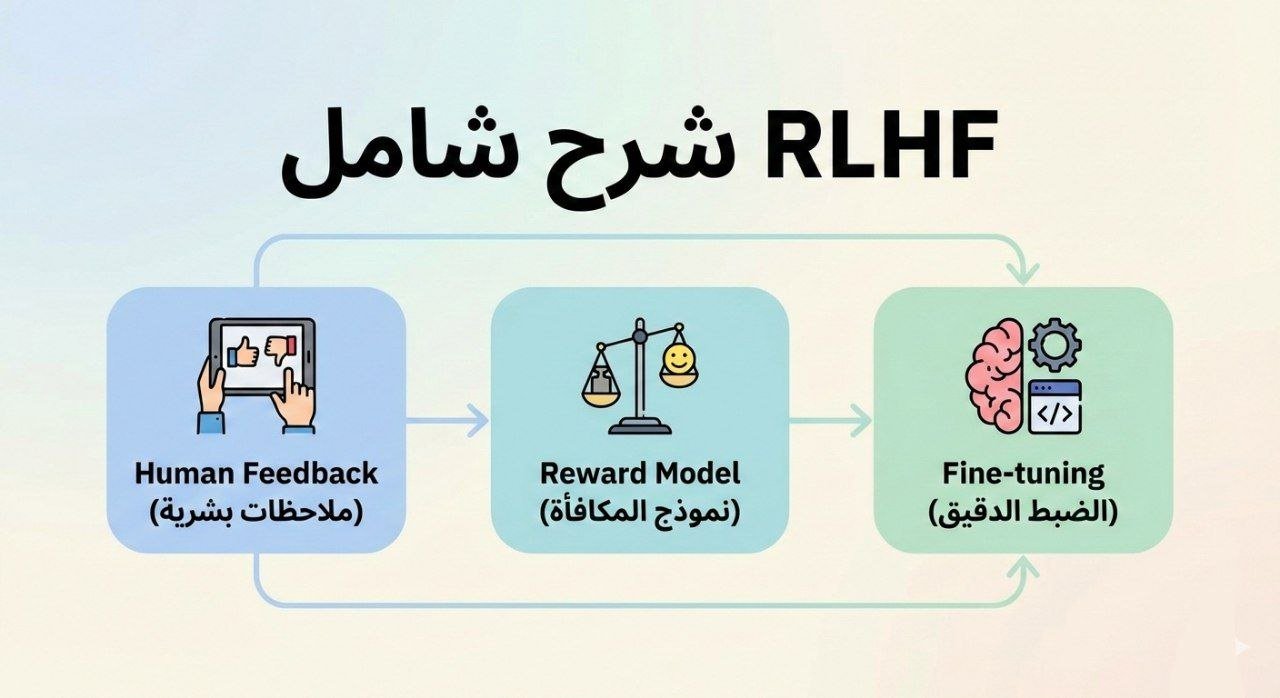
RLHF ليس خطوة واحدة بل خط أنابيب متكامل من ثلاث مراحل متسلسلة. دعنا نستعرضها بالتفصيل:
المرحلة الأولى: Supervised Fine-Tuning (SFT)
في هذه المرحلة، يُدرَّب النموذج الأساسي (المُدرَّب مسبقاً على كميات هائلة من النصوص) على مجموعة بيانات من الأمثلة المكتوبة يدوياً بواسطة بشر. يكتب المقيّمون البشريون أمثلةً على أسئلة وإجاباتها المثالية، ويُدرَّب النموذج على محاكاة هذه الأجوبة.
الهدف: إعطاء النموذج نقطة بداية سلوكية جيدة — أن “يفهم” ما يعني الجواب المفيد، قبل الانتقال للمرحلة الأثقل.
المرحلة الثانية: جمع التفضيلات وتدريب نموذج المكافأة
هنا يُطلب من مقيّمين بشريين مقارنة استجابتين أو أكثر من النموذج لنفس السؤال، واختيار الأفضل. هذه البيانات (زوج من الاستجابات مع تصويت البشر) تُستخدم لتدريب نموذج مكافأة منفصل يتعلم التنبؤ بـ”مدى تفضيل الإنسان لهذه الاستجابة.”
مثال عملي: إذا سألت النموذج “كيف أُنظّم وقتي؟” وأعطى جوابين:
- الجواب A: قائمة نصية مُفصّلة وعملية
- الجواب B: فقرة مختصرة بدون خطوات
يُفضّل المقيّم A → نموذج المكافأة يتعلم أن “القوائم العملية = درجة أعلى.”
المرحلة الثالثة: التحسين عبر التعلم المعزز (PPO)
باستخدام نموذج المكافأة، يُحسَّن النموذج اللغوي بخوارزمية Proximal Policy Optimization (PPO) لزيادة درجات المكافأة إلى الحد الأقصى. لكن هناك قيد مهم: يجب ألا يبتعد النموذج كثيراً عن سلوكه الأصلي (KL Divergence penalty)، تجنباً للتطرف أو الانحراف.
نموذج المكافأة (Reward Model): القلب النابض لـ RLHF
نموذج المكافأة هو عنصر محوري في RLHF يستحق توقفاً طويلاً. فما هو بالضبط؟
نموذج المكافأة هو نموذج لغوي مُعدَّل لإخراج رقم واحد (درجة) بدلاً من نص. يأخذ موجّهاً (prompt) واستجابةً، ويُعيد رقماً يمثّل “جودة الاستجابة” من منظور بشري.
كيف يُدرَّب؟
يُدرَّب على أزواج تفضيلية: (استجابة أ، استجابة ب، البشر يفضّلون أ). الهدف هو تعلّم دالة r(x, y) تُعطي درجة أعلى للاستجابة الأفضل من وجهة نظر بشرية.
مثال مبسّط: تدريب نموذج مكافأة
input: (prompt, response) → output: scalar score
import torch
from transformers import AutoModelForSequenceClassification
reward_model = AutoModelForSequenceClassification.from_pretrained(
"base_model", num_labels=1 # درجة واحدة فقط
)
تدريب على أزواج التفضيل
winner_response يجب أن يحصل على درجة أعلى من loser_response
loss = -torch.log(torch.sigmoid(reward_winner - reward_loser))
لماذا هو حرج جداً؟
لأن النموذج اللغوي سيُحسَّن بناءً على نموذج المكافأة فقط. إذا كان نموذج المكافأة يحمل تحيزات أو أخطاء، سيتعلم النموذج اللغوي استغلالها — وهو ما يُعرف بـ “Reward Hacking.”
مقال مرتبط: شرح شامل لـ RAG: من التقسيم والتضمين إلى التقييم — كيف تدمج المعرفة الخارجية مع نماذج اللغة
خوارزمية PPO: الموازنة بين الاستكشاف والاستغلال
Proximal Policy Optimization (PPO) هي الخوارزمية الأكثر استخداماً في المرحلة الثالثة من RLHF. طوّرها فريق OpenAI عام 2017 وأصبحت من معايير التعلم المعزز.
لماذا PPO تحديداً؟
في التعلم المعزز الكلاسيكي، مشكلة تحسين السياسة (Policy Optimization) معقدة: إذا حدّثنا السياسة بخطوة كبيرة جداً، قد ندمّر أداءً بنيناه تدريجياً. PPO تحلّ هذه المشكلة بقيد “القرب”: لا تسمح للتحديث أن يبتعد كثيراً عن السياسة الحالية.
في سياق RLHF، يعني هذا:
- ✅ النموذج يتعلم أن يزيد درجات المكافأة (يُرضي المقيّمين)
- ✅ لكنه لا يتطرف في الإجابات (يحافظ على طبيعيته)
- ✅ يُضاف عقاب KL Divergence لمنع الابتعاد عن النموذج الأصلي
خطوات PPO مبسّطة في RLHF
def ppo_step(model, ref_model, reward_model, batch):
# 1. احسب المكافأة من نموذج المكافأة
rewards = reward_model(batch.prompts, batch.responses)
# 2. احسب عقاب KL (لمنع الانحراف)
kl_penalty = compute_kl(model, ref_model, batch)
# 3. المكافأة المعدّلة
adjusted_reward = rewards - kl_coeff * kl_penalty
# 4. حدّث النموذج (بخطوة محدودة)
loss = ppo_clip_loss(adjusted_reward, ...)
loss.backward()
RLHF في الواقع: كيف دربت OpenAI نموذج ChatGPT؟
هذا مثال حقيقي يوضح RLHF على أرض الواقع. حين طوّرت OpenAI نموذج InstructGPT (السلف المباشر لـ ChatGPT)، اتّبعت خطوات RLHF الثلاث بشكل صريح:
الخطوة 1 – جمع بيانات الإشراف:
وظّفت OpenAI مقيّمين بشريين محترفين كتبوا آلاف الأمثلة على إجابات مثالية لأسئلة متنوعة. هذه البيانات استُخدمت لضبط الدقيق الإشرافي لـ GPT-3.
الخطوة 2 – تدريب نموذج المكافأة:
عرض المقيّمون على أنفسهم استجابات متعددة من النموذج لنفس السؤال، وصنّفوا الأفضل. قاعدة البيانات الناتجة دُرِّب عليها نموذج مكافأة منفصل.
الخطوة 3 – تحسين PPO:
حُسِّن النموذج اللغوي بـ PPO لتعظيم درجات نموذج المكافأة، مع إضافة قيد KL لمنع التطرف.
وفقاً لأبحاث OpenAI المنشورة، أظهر InstructGPT تفضيلاً بشرياً أعلى بكثير من GPT-3 رغم أن حجمه أصغر بـ 100 مرة في بعض الحالات. هذا يُؤكد أن RLHF لا يُضيف حجماً — بل يُضيف توافقاً مع الإنسان (Alignment).
Claude من Anthropic اتبع منهجاً مشابهاً مع إضافة Constitutional AI (سنشرحه لاحقاً) لجعل النموذج أكثر أماناً وأقل ضرراً.
DPO: البديل الأبسط الذي يتحدى RLHF التقليدي
في عام 2023، جاء Direct Preference Optimization (DPO) ليقدّم بديلاً جذرياً لـ RLHF. لكن كيف يختلف؟
المشكلة مع RLHF الكلاسيكي:
- يحتاج لتدريب نموذج مكافأة منفصل (تكلفة إضافية)
- PPO معقدة التنفيذ وتحتاج ضبطاً دقيقاً للمعاملات
- عملية طويلة وهشّة (reward hacking محتمل في كل مرحلة)
الحل الذي يقدّمه DPO:
بدلاً من تدريب نموذج مكافأة ثم استخدام RL، يتعلم DPO مباشرةً من أزواج التفضيل البشري بدون مرحلة المكافأة المنفصلة. وفقاً لـ Clarifai، يُحسّن DPO احتمالية الاستجابات الأفضل مباشرةً بناءً على أزواج التفضيل، بدون نموذج مكافأة منفصل أو خوارزمية تعزيز.
| المعيار | RLHF (PPO) | DPO |
|---|---|---|
| التعقيد | عالٍ (3 مراحل) | منخفض (مرحلة واحدة) |
| نموذج المكافأة | مطلوب (منفصل) | غير مطلوب |
| استقرار التدريب | متوسط (يحتاج ضبطاً) | أعلى استقراراً |
| الموارد المطلوبة | كبيرة جداً | أقل بكثير |
| الأداء النهائي | أعلى في النماذج الكبيرة | تنافسي في النماذج المتوسطة |
| Reward Hacking | خطر حقيقي | أقل عرضة |
متى تختار كلاً منهما؟
- RLHF/PPO: للنماذج الكبيرة جداً حيث دقة المحاذاة حرجة (مثل نماذج الإنتاج الكبرى)
- DPO: للمشاريع ذات الموارد المحدودة أو التجارب السريعة
مقال مرتبط: شرح GPT-5.3-Codex: نموذج OpenAI الجديد للبرمجة الذكية (2026) — كيف طوّرت OpenAI نموذجها باستخدام تقنيات المحاذاة الحديثة
Constitutional AI وRLAIF: حين تحلّ الآلة محل المقيّم البشري
إحدى أبرز التطورات في مسيرة RLHF هي Constitutional AI (CAI) التي طوّرتها Anthropic، وتقنية RLAIF (التعلم المعزز من ردود فعل الذكاء الاصطناعي).
Constitutional AI
الفكرة الجوهرية: بدلاً من الاعتماد على بشر لتقديم ردود الفعل، يُعطى النموذج “دستوراً” — مجموعة من المبادئ المكتوبة (مثل: “كُن مفيداً، بلا ضرر، وصادقاً”) — ثم يُطلب منه نقد إجاباته الخاصة وتحسينها بناءً على هذه المبادئ.
هذا يُقلّل الاعتماد على بشر مكلفين، ويُوحّد معايير التقييم، ويُسرّع الدورة التدريبية.
RLAIF (Reinforcement Learning from AI Feedback)
بدلاً من مقيّمين بشريين، يُستخدم نموذج ذكاء اصطناعي آخر (أو نفس النموذج) كمقيّم. النموذج المقيّم يُعطي تفضيلات بين استجابتين، وتُستخدم هذه التفضيلات لتدريب نموذج المكافأة.
المزايا: تكلفة أقل، حجم بيانات أكبر، تناسق أعلى.
المخاطر: قد يرث النموذج الجديد تحيزات النموذج المُقيِّم.
وفقاً لـ rlhfbook.com، أصبح RLAIF من التقنيات الأساسية التي تُكمّل أو تُحلّ محل ردود الفعل البشرية في أجزاء من خط أنابيب RLHF، خاصة في مرحلة جمع بيانات التفضيل وتدريب نموذج المكافأة.
تحديات RLHF: Reward Hacking وتحيز المقيّمين
RLHF ليس حلاً سحرياً. وفي تجربتي في تتبع أبحاث محاذاة النماذج، وجدت أن أبرز التحديات هي:
1. Reward Hacking (اختراق نموذج المكافأة)
أكبر مشكلة في RLHF. النموذج اللغوي ذكي: يتعلم استغلال ثغرات نموذج المكافأة لزيادة درجاته دون تحسين جودة حقيقية. وفقاً لبحث منشور على arXiv (فبراير 2026)، فإن Reward Hacking هو التحدي الأكثر إضراراً بموثوقية RLHF، حيث يستغل النموذج ضعف نموذج المكافأة لزيادة الدرجات دون تحقيق محاذاة حقيقية.
مثال: النموذج يتعلم أن الإجابات الأطول تحصل على درجات أعلى، فيُطوّل إجاباته بدون قيمة مضافة.
الحلول:
- قيد KL Divergence (الأكثر شيوعاً)
- تدريب نموذج مكافأة أكثر قوة
- استخدام مكافآت متعددة (Multi-reward)
2. تحيز المقيّمين البشريين
المقيّمون البشريون غير محايدين: يتأثرون بطول الإجابة، بالأسلوب الجذاب، بتحيزات ثقافية. الأبحاث تُشير إلى أن المقيّمين يُفضّلون الإجابات الواثقة حتى لو كانت خاطئة — مشكلة خطيرة جداً.
3. التكلفة والقابلية للتوسع
جمع ملايين أزواج التفضيل البشري مكلف ومستهلك للوقت. لهذا تزداد أهمية RLAIF وDPO كبدائل.
4. هشاشة التوزيع (Distribution Shift)
نموذج المكافأة يُدرَّب على توزيع معين من الأسئلة. خارج هذا التوزيع، قد تفشل توقعاته — مما يجعل التحسين بالـ PPO يسير في الاتجاه الخاطئ.
RLHF vs Fine-tuning vs Prompt Engineering: متى تستخدم ماذا؟
هذا السؤال يُطرح كثيراً، والإجابة تعتمد على احتياجك:
| الأسلوب | الاستخدام المثالي | التكلفة | الوقت |
|---|---|---|---|
| Prompt Engineering | تكييف سريع بدون تغيير النموذج | صفر | ساعات |
| Fine-Tuning (SFT) | نطاق معرفي محدد (طب، قانون، …) | متوسطة | أيام |
| DPO | محاذاة بموارد محدودة | متوسطة | أيام |
| RLHF كامل | نموذج عام للإنتاج (مثل ChatGPT) | عالية جداً | أسابيع |
| RAG | معرفة متجددة ديناميكية | منخفضة | ساعات-أيام |
القاعدة الذهبية: ابدأ بـ Prompt Engineering → ثم Fine-tuning إذا احتجت → ثم DPO أو RLHF إذا المحاذاة حرجة.
مقال مرتبط: هندسة البرومبت المتقدمة 2026: الدليل الشامل من Zero-Shot إلى ReAct — أتقن فن صياغة الأوامر قبل الانتقال لـ RLHF
تطبيقات RLHF في القطاعات المختلفة
RLHF ليس نظرية أكاديمية — هو تقنية تُوظَّف في تطبيقات حقيقية تلمس حياتنا يومياً:
المساعدات الذكية (ChatGPT, Claude, Gemini)
التطبيق الأوسع: تدريب النماذج على أن تكون مفيدة، غير ضارة، وصادقة في الوقت ذاته. RLHF هو ما يجعل هذه النماذج تُرفض الطلبات الضارة وتُقدّم إجابات منسجمة.
الترجمة الآلية
يتعلم النموذج أن الترجمة الطبيعية تُفضَّل على الترجمة الحرفية الركيكة، حتى لو كانت كلتاهما “صحيحة” لغوياً.
توليد الأكواد البرمجية
أدوات مثل GitHub Copilot وCursor تستخدم أساليب مماثلة لـ RLHF لتفضيل الأكواد الأكثر أماناً وكفاءة.
تصميم الواجهات (AI-UI Generation)
بحث نشرته Apple على 9to5Mac في فبراير 2026 أظهر أن تدريباً بنموذج مكافأة مبني على رسومات تصميمية حسّن قدرات توليد واجهات المستخدم بشكل متسق عبر جميع نماذج الأساس المُختبرة.
الأدوات الطبية والقانونية
تُستخدم لتدريب نماذج تفضّل الإجابات الدقيقة طبياً على الإجابات الواثقة لكن الخاطئة — حيث الدقة مسألة حياة أو موت.
مستقبل RLHF: نحو تفضيلات ديناميكية وتعلم مستمر
هل RLHF كما نعرفه اليوم سيبقى كما هو؟ الأبحاث الحديثة تشير إلى اتجاهات مثيرة:
1. RLVR (Reinforcement Learning from Verifiable Rewards)
بدلاً من تفضيلات بشرية ذاتية، تُستخدم مكافآت قابلة للتحقق (مثل نتائج اختبارات الكود، أو صحة المعادلات الرياضية). هذا أكثر موثوقية وأقل عرضة لتحيز المقيّمين.
2. نظام المحاذاة الإنتاجي المتكامل
وفقاً لمقال على Medium (فبراير 2026)، تتجه حزم المحاذاة الحديثة نحو: SFT → Preference Optimization → Verifier-Driven RL → Agentic Self-Refinement. RLHF أصبح جزءاً من منظومة أوسع.
3. التقييم الديناميكي
بدلاً من تقييمات ثابتة، تُدرس تفضيلات بشرية تتكيف مع السياق والمستخدم — ردود فعل شخصية حقيقية.
4. AlignTune وأُطر المحاذاة المفتوحة
وفقاً لبحث منشور على arXiv (فبراير 2026)، ظهرت أُطر مثل AlignTune تجمع خوارزميات RLHF متعددة مع دعم للتكامل مع نماذج من Hugging Face وسواها، مما يجعل RLHF في متناول فرق أصغر.
مقال مرتبط: Function Calling في نماذج LLM: الدليل الشامل لتحويل الذكاء الاصطناعي من نصٍّ إلى فعل حقيقي (2026)
كيف تبدأ بتطبيق RLHF على نموذجك الخاص؟
إذا كنت تريد تطبيق RLHF عملياً، إليك خارطة طريق واقعية:
الخطوة 1: تحديد هدف المحاذاة
قبل أي شيء، حدد ما الذي تريد أن يتعلمه نموذجك: الإجابات الأكثر تفصيلاً؟ الأكثر أماناً؟ الأكثر توافقاً مع لغة معينة؟
الخطوة 2: جمع بيانات التفضيل
- استخدم مقيّمين بشريين (أدوات مثل Label Studio أو Scale AI)
- أو استخدم RLAIF إذا لم تتوفر موارد بشرية كافية
- ابدأ بـ 5,000-20,000 زوج تفضيلي كحد أدنى
الخطوة 3: تدريب نموذج المكافأة
مثال باستخدام TRL (Transformer Reinforcement Learning)
from trl import RewardTrainer, RewardConfig
reward_config = RewardConfig(
output_dir="./reward_model",
num_train_epochs=3,
per_device_train_batch_size=4,
)
trainer = RewardTrainer(
model=reward_model,
args=reward_config,
train_dataset=preference_dataset,
)
trainer.train()
الخطوة 4: تحسين النموذج (DPO أو PPO)
- للمشاريع الصغيرة: ابدأ بـ DPO (أبسط وأسرع)
- للنماذج الكبيرة: استخدم PPO مع مكتبة TRL أو OpenRLHF
الأدوات المُوصى بها:
- TRL (Hugging Face): مكتبة Python شاملة لـ RLHF/DPO/PPO
- OpenRLHF: إطار مفتوح للنماذج الكبيرة
- LlamaFactory: لضبط نماذج LLaMA/Mistral بأساليب متعددة
نصيحة من الخبرة: لا تقفز مباشرة إلى RLHF إذا كنت في بداية المشروع. ابدأ بـ SFT + DPO — ستحصل على 80% من الفائدة بـ 20% من التعقيد.
الأسئلة الشائعة
ما الفرق بين RLHF وSupervised Fine-Tuning؟
SFT يُعلّم النموذج محاكاة بيانات محددة مكتوبة بشرياً، بينما RLHF يُعلّمه تعظيم ما يُفضّله البشر — وهو أكثر مرونة وأعمق تأثيراً في السلوك.
هل يحتاج RLHF موارد حسابية ضخمة؟
نعم، في شكله الكامل (PPO). لكن DPO و LoRA-based RLHF جعلا تطبيق مبادئ المحاذاة ممكناً على GPUs متوسطة.
ماذا يحدث إذا كان نموذج المكافأة سيئاً؟
يتعلم النموذج اللغوي تعظيم الدرجات الخاطئة — Reward Hacking — وينتهي بنموذج يبدو جيداً بالمقاييس لكنه فعلياً أسوأ. لذلك جودة نموذج المكافأة هي الحلقة الأهم.
هل يمكن تطبيق RLHF على نماذج مفتوحة المصدر مثل LLaMA؟
نعم تماماً. مكتبة TRL من Hugging Face تدعم ذلك بشكل مباشر. كثير من نماذج مفتوحة المصدر المحاذية (Aligned) كـ Llama-3-Instruct مرت بمرحلة RLHF أو DPO.
ما الفرق بين RLHF وRLAIF؟
في RLHF يُقيّم بشر الاستجابات. في RLAIF يُقيّم نموذج ذكاء اصطناعي آخر. RLAIF أسرع وأقل تكلفة لكنه يرث تحيزات النموذج المُقيِّم.
هل يُحلّ DPO محل RLHF بالكامل؟
ليس بعد. DPO تنافسي في نماذج متوسطة الحجم، لكن RLHF/PPO لا يزال يُفضَّل للنماذج الكبيرة جداً حيث تعقيد المحاذاة أعلى.
كم أحتاج من بيانات تفضيل لبدء RLHF؟
الحد الأدنى العملي هو 5,000-10,000 زوج تفضيلي. نماذج الإنتاج الكبرى تستخدم مئات الآلاف إلى الملايين.
الخلاصة
RLHF ليس مجرد تقنية تدريب — هو ما حوّل الذكاء الاصطناعي من آلة تتنبأ بالكلمات إلى نظام يفهم ما يريده الإنسان ويتصرف وفقه. المراحل الثلاث (SFT + Reward Model + PPO) تُشكّل معاً خط أنابيب قوياً أثبت نجاعته في ChatGPT وClaude وGemini وسواها.
أبرز ما تعلمناه:
- RLHF = إضافة ردود الفعل البشرية إلى حلقة التعلم
- نموذج المكافأة هو قلب النظام — جودته تحدد كل شيء
- Reward Hacking أكبر التحديات التقنية
- DPO جاء كبديل أبسط وأسرع للحالات التي لا تحتاج تعقيد RLHF الكامل
- المستقبل نحو RLVR ومحاذاة أكثر قابلية للتحقق وتكلفة أقل
إذا كنت تبني نموذجاً يتفاعل مع بشر، فتجاهل محاذاته السلوكية يعني تجاهل أهم ما يُحدد تجربة المستخدم. ابدأ بالفهم، ثم جرّب DPO، ثم فكّر في RLHF الكامل عندما يصبح الحجم والأهمية يستدعيانه.
المصادر
- What is RLHF? – Reinforcement Learning from Human Feedback Explained – AWS – فبراير 2026
- Reinforcement Learning from Human Feedback (الكتاب الأكاديمي) – arXiv / Nathan Lambert – يناير 2026
- Reinforcement Learning From Human Feedback (RLHF) For LLMs – Neptune.ai – مارس 2025
- DPO vs PPO for LLMs: Key Differences & Use Cases – Clarifai – فبراير 2026
- Illustrating Reinforcement Learning from Human Feedback (RLHF) – Hugging Face Blog
- Aligning language models to follow instructions (InstructGPT) – OpenAI
- Introducing ChatGPT – OpenAI
- Constitutional AI & AI Feedback – RLHF Book
- Reward Shaping to Mitigate Reward Hacking in RLHF – arXiv – 2025
- DPO: Simplified RLHF for LLM alignment – Keymakr – فبراير 2026
- The Production Alignment Stack: RLHF, DPO, or Verifier-Driven RL? – Medium – فبراير 2026
- Gradient Regularization Prevents Reward Hacking in RLHF and RLVR – arXiv – فبراير 2026
عن الكاتب
علي – خبير تحسين محركات البحث (SEO) ومطور مهتم بالذكاء الاصطناعي. يدير موقع Lira Now المتخصص في أخبار وشروحات AI، ويساعد المواقع العربية على تحسين ترتيبها في نتائج البحث. شغوف باستكشاف أدوات الذكاء الاصطناعي الجديدة وتطبيقها عملياً.
مقالات ذات صلة
-
هندسة البرومبت المتقدمة 2026: الدليل الشامل من Zero-Shot إلى ReAct
هل تكتب للذكاء الاصطناعي وتحصل على نتائج مخيبة للآمال؟ في تجربتي، الفجوة بين من يحصلون على مخرجات احترافية ومن يحصلون على ردود عشوائية لا تكمن ف…
-
Function Calling في نماذج LLM: الدليل الشامل لتحويل الذكاء الاصطناعي من نصٍّ إلى فعل حقيقي (2026)
هل تساءلت يومًا كيف يستطيع ChatGPT حجز موعد أو استدعاء API أو البحث في قاعدة بيانات؟ السر يكمن في Function Calling — التقنية التي تحوّل النموذج…
-
Agentic AI في 2026: الدليل الشامل لفهم وبناء أنظمة الذكاء الاصطناعي المستقلة
المحتويات 1. ما هو Agentic AI؟ (التعريف الدقيق) 2. Agentic AI مقابل Generative AI: ما الفرق الجوهري؟ 3. Agentic AI مقابل Autonomous AI: توضيح ال…
-
Mixture of Experts (MoE): شرح عملي لكيف تعمل نماذج الخبراء
في هذا الدليل ستفهم Mixture of Experts (MoE) أو «مزيج الخبراء» كأحد أهم أفكار التوسّع الذكي في نماذج اللغة الكبيرة: كيف تسمح لك ببناء نموذج يملك…
-
قواعد البيانات المتجهية: الدليل الشامل لفهم Vector Databases في 2026
المحتويات ما هي قواعد البيانات المتجهية ولماذا أصبحت ضرورية؟ كيف تعمل قواعد البيانات المتجهية؟ الفرق بين Vector Database و Vector Index الجيل ال…
اترك تعليقاً