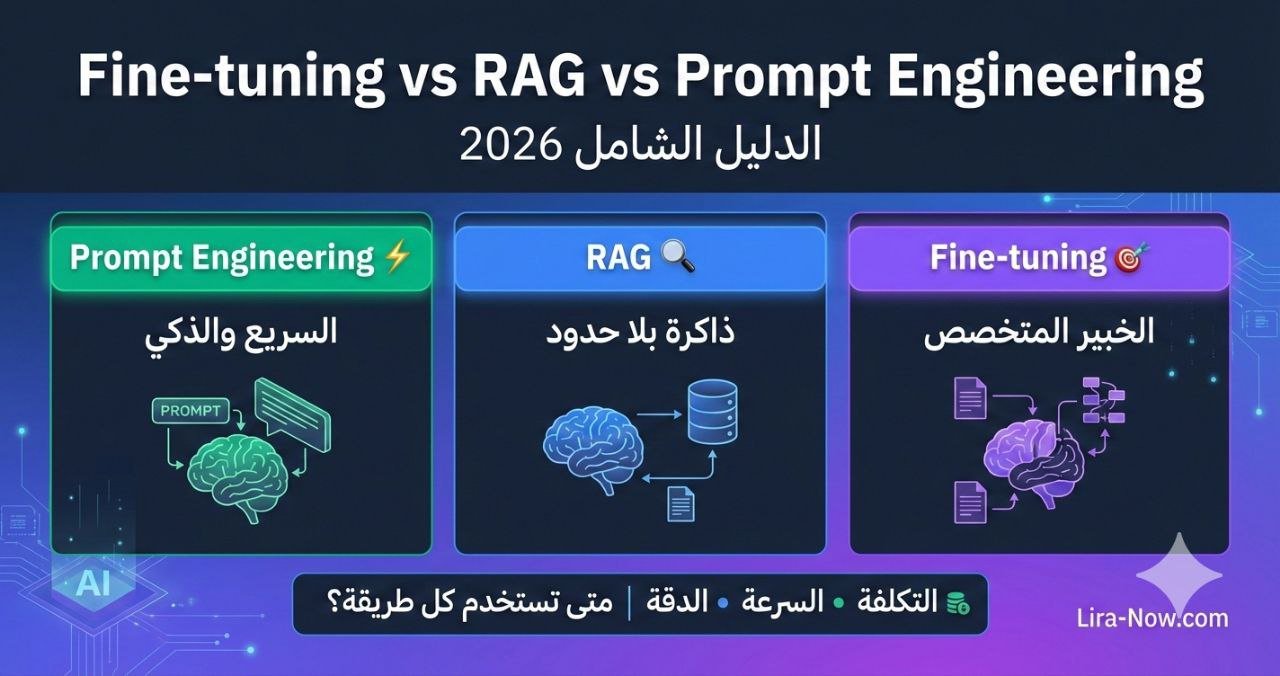
في عالم الذكاء الاصطناعي المتسارع، يواجه المطورون وقادة المنتجات سؤالاً متكرراً: كيف أجعل النموذج يعرف بياناتي الخاصة؟ هل أقوم بتدريبه من جديد (Fine-tuning)؟ أم أربطه بقاعدة معرفة (RAG)؟ أم يكفي كتابة أوامر ذكية (Prompt Engineering)؟
في عام 2026، تغيرت الإجابة. لم تعد المسألة “هذا أو ذاك”، بل أصبحت “متى وكيف تدمج بينهم”. مع انخفاض تكلفة النماذج الذكية (مثل GPT-5.3 وClaude Sonnet 4.6) وظهور تقنيات هجينة، أصبح اختيار الاستراتيجية الصحيحة هو العامل الحاسم في نجاح مشروعك أو فشله.
هذا الدليل الشامل سيأخذك في رحلة عملية من الصفر، لنقارن بين التقنيات الثلاث بالأرقام، التكاليف، والنتائج، ونساعدك على اتخاذ القرار الصحيح لمشروعك القادم.
المحتويات
- مقدمة: لماذا يفشل الجميع في الاختيار؟
- Prompt Engineering: البداية السريعة والذكية
- RAG (Retrieval Augmented Generation): ذاكرة بلا حدود
- Fine-tuning: بناء الخبير المتخصص
- مقارنة شاملة: التكلفة، السرعة، والدقة (أرقام 2026)
- النهج الهجين (Hybrid Approach): المستقبل الآن
- دراسة حالة عملية: بناء مساعد قانوني ذكي
- شجرة اتخاذ القرار: كيف تختار لمشروعك؟
- أسئلة شائعة (FAQ)
- الخاتمة والخطوات القادمة
1. مقدمة: لماذا يفشل الجميع في الاختيار؟
الخطأ الأكبر الذي نراه في 2026 هو القفز المباشر إلى Fine-tuning. يعتقد الكثيرون أن “تدريب النموذج” هو الحل السحري لأي مشكلة. الحقيقة الصادمة؟ 80% من حالات الاستخدام لا تحتاج إلى Fine-tuning، بل قد يؤدي لنتائج أسوأ وتكاليف باهظة.
تخيل أنك تريد تعليم موظف جديد (النموذج) كيفية العمل في شركتك:
* Prompt Engineering: مثل إعطائه ورقة تعليمات واضحة قبل كل مهمة.
* RAG: مثل إعطائه إمكانية الوصول لأرشيف الشركة ليبحث فيه عند الحاجة.
* Fine-tuning: مثل إرساله لجامعة متخصصة ليدرس طريقة عمل شركتك لسنوات.
هل سترسل موظفاً للجامعة ليتعلم “كيفية إعداد القهوة في المكتب”؟ بالطبع لا. ولكن هل ستكتفي بورقة تعليمات لعملية جراحية معقدة؟ أيضاً لا. السر يكمن في التوازن.
2. Prompt Engineering: البداية السريعة والذكية
هندسة الأوامر (Prompt Engineering) ليست مجرد كتابة “اكتب لي مقالاً”. في 2026، تطورت لتصبح علامة تجارية للهندسة المعرفية.
ما هو؟
هو فن صياغة المدخلات (Prompts) لتوجيه النموذج نحو المخرجات المطلوبة دون تغيير وزنه أو ذاكرته.
متى تستخدمه؟
* للنماذج الأولية (Prototyping): اختبار الفكرة في ساعات.
* للمهام العامة: التلخيص، الترجمة، إعادة الصياغة.
* عندما تكون التعليمات قصيرة: أقل من 100-200 صفحة (بفضل سياق النماذج الكبير مثل 2M tokens في Gemini 3 Deep Seek).
تقنيات متقدمة في 2026:
- Chain-of-Thought (CoT): إجبار النموذج على “التفكير بصوت عالٍ” قبل الإجابة.
- Few-Shot Prompting: إعطاء 3-5 أمثلة في الأمر لتقليد النمط.
- Meta-Prompting: جعل النموذج يكتب الـ Prompt لنفسه أو لنموذج آخر.
💡 نصيحة خبير: ابدأ دائماً بـ Prompt Engineering. إذا تمكنت من الوصول لـ 80% من الجودة المطلوبة، فقد وفرت آلاف الدولارات. لا تنتقل للخطوة التالية إلا إذا فشلت هنا.
3. RAG (Retrieval Augmented Generation): ذاكرة بلا حدود
تقنية RAG هي “المعيار الذهبي” لتطبيقات الأعمال في 2026. ببساطة، هي تمنح النموذج “كتاباً مفتوحاً” ليغش منه الإجابات.
كيف يعمل؟
- المستخدم يسأل: “ما هي سياسة الإجازات الجديدة؟”
- النظام يبحث: في قاعدة بيانات الشركة عن وثائق “الإجازات”.
- النظام يدمج: السؤال + الوثائق التي وجدها في Prompt واحد.
- النموذج يجيب: بناءً على المعلومات المرفقة فقط.
المميزات القاتلة:
* حداثة المعلومات: عدّل ملف PDF في قاعدة البيانات، وسيعرف النموذج المعلومة فوراً (بدون إعادة تدريب).
* المصداقية (Citation): يمكن للنموذج أن يخبرك “وجدت هذه المعلومة في صفحة 12 من ملف HR.pdf”.
* الأمان: يمكنك تحديد الصلاحيات (من يرى ماذا) في مرحلة البحث.
العيوب:
* زمن الاستجابة (Latency): عملية البحث والقراءة تضيف ثوانٍ للإجابة.
* السياق المفقود: إذا فشل البحث في إيجاد الملف الصحيح، سيفشل النموذج في الإجابة (Garbage In, Garbage Out).
التكلفة (تقديرات 2026):
حسب تقرير من Matillion (نوفمبر 2025)، تكلفة تشغيل نظام RAG تتراوح بين 70$ إلى 1000$ شهرياً للشركات المتوسطة، معظمها تكاليف استدعاء API وتخزين Vector DB.
4. Fine-tuning: بناء الخبير المتخصص
هنا نغير “دماغ” النموذج نفسه. نأخذ نموذجاً عاماً (مثل GPT-4.1) وندربه على بياناتنا ليصبح متخصصاً.
متى يكون ضرورياً؟
* لتغيير السلوك أو النبرة: تريد نموذجاً يتحدث كـ “محامي سعودي في القرن الثامن عشر” أو “قرصان”.
* للغات/لهجات نادرة: تدريب النموذج على اللهجة المغربية الدارجة أو المصطلحات الطبية المعقدة.
* لتقليل التكلفة على المدى الطويل: نموذج صغير (مثل GPT-4.1 mini) مدرب جيداً قد يتفوق على نموذج ضخم (GPT-5) وتكلفته أقل بـ 10 مرات.
التكلفة الصادمة (Hidden Costs):
حسب تحليل من Azure Noob (فبراير 2026)، تكلفة استضافة نموذج مدرب (Fine-tuned Model Hosting) على Azure OpenAI قد تصل إلى 1,836$ شهرياً كحد أدنى، حتى لو لم تستخدمه!
* التدريب: تكلفة مرة واحدة (مثلاً 50-500$).
* الاستضافة: تكلفة مستمرة باهظة (لأنك تحجز سيرفر خاص لنموذجك).
⚠️ تحذير: الـ Fine-tuning لا يضيف “معلومات جديدة” (حقائق)، بل يضيف “أنماط سلوك”. إذا دربت نموذجاً على “أسعار الأسهم اليوم”، سينساها غداً أو يهلوس بها. للحقائق، استخدم RAG.
5. مقارنة شاملة: التكلفة، السرعة، والدقة (أرقام 2026)
لنضع النقاط على الحروف بمقارنة مباشرة:
| المعيار | Prompt Engineering | RAG | Fine-tuning |
|---|---|---|---|
| أفضل استخدام | اختبار الأفكار، المهام العامة | بيانات متغيرة، حاجة للمصادر | تخصيص النبرة، لغات خاصة |
| حداثة البيانات | تعتمد على تاريخ تدريب النموذج | ✅ فورية (Real-time) | ❌ ثابتة (تتطلب إعادة تدريب) |
| تقليل الهلوسة | متوسط | ⭐⭐⭐ ممتاز (مع المصادر) | ⭐ ضعيف (قد يختلق حقائق) |
| التكلفة الأولية | منخفضة جداً (وقت المطور) | متوسطة (إعداد Pipeline) | عالية (تجهيز البيانات + تدريب) |
| التكلفة التشغيلية | حسب الاستخدام (Tokens) | أعلى قليلاً (بحث + Tokens) | 💸 باهظة (استضافة مخصصة) |
| الخبرة المطلوبة | مبتدئ / متوسط | متوسط / متقدم | خبير ML / Data Science |
6. النهج الهجين (Hybrid Approach): المستقبل الآن
لماذا تختار واحداً بينما يمكنك الجمع بين الأفضل؟ الاتجاه السائد في 2026 هو Fine-tuning for Form, RAG for Facts.
المعادلة الناجحة:
- استخدم Fine-tuning لتعليم النموذج “كيف يتحدث” (أسلوب الشركة، هيكل JSON، اللغة العامية).
- استخدم RAG لإعطاء النموذج “ماذا يقول” (المعلومات، الأسعار، القوانين).
حسب ورقة بحثية نُشرت في arXiv (أكتوبر 2025)، حقق هذا النهج الهجين دقة أعلى بنسبة 18% من استخدام RAG وحده، وأعلى بنسبة 40% من Fine-tuning وحده في المهام المعقدة.
مثال: مساعد خدمة عملاء لشركة اتصالات.
* Fine-tuning: ليتعلم كيف يكون ودوداً، صبوراً، ويستخدم مصطلحات الشركة الداخلية (“باقة واجد”، “خدمة جوّي”).
* RAG: ليعرف رصيد العميل الحالي، آخر الفواتير، وعروض اليوم المتاحة.
7. دراسة حالة عملية: بناء مساعد قانوني ذكي
لنفترض أننا نبني “مستشار قانوني آلي” للقانون السعودي.
المحاولة 1: Prompt Engineering فقط
* المدخل: “أنت محام سعودي. ما عقوبة السرقة؟”
* النتيجة: إجابة عامة جيدة، لكنها قد تفتقر للمواد القانونية الدقيقة وأرقام المراسيم الملكية الحديثة.
المحاولة 2: Fine-tuning فقط
* العملية: تدريب GPT-4 على 10,000 قضية سابقة.
* النتيجة: النموذج يتحدث بأسلوب قانوني مبهر جداً (“إلحاقاً لما ورد في…”).
* المشكلة: عندما سُئل عن قانون صدر “أمس”، أجاب بقانون قديم ملغى بثقة تامة! (كارثة قانونية).
المحاولة 3: RAG (الحل الأمثل)
* العملية: ربط النموذج بقاعدة بيانات تحتوي على نظام المرافعات الشرعية ونظام العمل (محدثة يومياً).
* النتيجة: “حسب المادة 77 من نظام العمل المعدل بتاريخ…، فإن التعويض هو…”
* الميزة: دقة 100% في المواد القانونية، وقدرة على الاستشهاد بالمصدر.
الحكم: لهذا المشروع، RAG هو الفائز بلا منازع.
8. شجرة اتخاذ القرار: كيف تختار لمشروعك؟
استخدم هذا المخطط البسيط قبل بدء أي مشروع:
- هل تحتاج لمعرفة خارجية (بيانات الشركة، أخبار اليوم)؟
* نعم: RAG (لا تفكر مرتين).
* لا: انتقل للسؤال التالي.
- هل تحتاج لتغيير جذري في الأسلوب أو التنسيق (صوت شخصية، كود خاص)؟
* نعم: هل يمكنك وصفه في Prompt؟
* نعم: Prompt Engineering.
* لا (معقد جداً): Fine-tuning.
* لا: Prompt Engineering.
- هل لديك ميزانية تتجاوز 2000$ شهرياً للاستضافة؟
* لا: تجنب Fine-tuning واستثمر في تحسين RAG.
9. أسئلة شائعة (FAQ)
س: هل يمكنني عمل Fine-tuning لنموذج مفتوح المصدر (مثل Llama 3) وتشغيله محلياً؟
ج: نعم، وهذا يوفر تكلفة الاستضافة الشهرية لـ OpenAI/Azure، لكنك ستحتاج لعتاد قوي (GPUs) وصيانة دورية.
س: هل RAG بطيء؟
ج: في 2026، تحسنت السرعة جداً. باستخدام قواعد بيانات Vector حديثة وتقنيات مثل “Speculative Decoding”، أصبح التأخير غير ملحوظ (أقل من 500ms إضافية).
س: كم عدد الوثائق التي يمكنني وضعها في RAG؟
ج: الملايين! لا يوجد حد عملي. شركات مثل Google وMicrosoft تستخدم RAG للبحث في مليارات الصفحات.
10. الخاتمة والخطوات القادمة
في عام 2026، الذكاء ليس في “تدريب” النموذج، بل في “توصيله”.
* ابدأ دائماً بـ Prompt Engineering.
* أضف RAG عندما تحتاج لبياناتك الخاصة.
* احتفظ بـ Fine-tuning للحالات النادرة التي تتطلب تعديل السلوك الجذري.
تذكر: التكنولوجيا وسيلة وليست غاية. المستخدم لا يهتم إذا كنت تستخدم RAG أو سحر الفودو، هو يهتم فقط بالإجابة الصحيحة.
—
علي – خبير تحسين محركات البحث (SEO) ومطور مهتم بالذكاء الاصطناعي. يدير موقع Lira Now المتخصص في أخبار وشروحات AI.
عن الكاتب
علي – خبير تحسين محركات البحث (SEO) ومطور مهتم بالذكاء الاصطناعي. يدير موقع Lira Now المتخصص في أخبار وشروحات AI، ويساعد المواقع العربية على تحسين ترتيبها في نتائج البحث. شغوف باستكشاف أدوات الذكاء الاصطناعي الجديدة وتطبيقها عملياً.
المصادر
- RAG vs. Fine-tuning: What’s the Difference? – IBM – November 2025
- Balancing Fine-tuning and RAG: A Hybrid Strategy – arXiv – October 2025
- vs-fine-tuning-what-us-product-teams-are-actually-
choosing/” target=”_blank” rel=”noopener”>What US Product Teams Are Actually Choosing in 2026 – Breaking AC – February 2026 - OpenAI API Pricing Page – OpenAI Official – February 2026
- Claude Pricing Plans – Anthropic Official – February 2026
- مقالات ذات صلة
-
شرح شامل لـ RAG: من التقسيم والتضمين إلى التقييم
توليد النص المعزز بالاسترجاع (RAG) هو أسلوب يربط نماذج اللغة ببيانات حديثة أو خاصة عبر مرحلة استرجاع قبل التوليد، فيمنح الإجابات دقة أعلى ويقلل…
-
دليلك الشامل لـ OpenClaw 2026: مساعد الذكاء الاصطناعي الذي يعمل على أجهزتك ويحقق دخلاً حقيقياً
المحتويات المقدمة ما هو OpenClaw بالضبط؟ آخر تحديثات OpenClaw: الإصدار 2026.2.16 كيفية إعداد OpenClaw: دليل شامل للمبتدئين Skills: قلب قوة OpenC…
-
دليل شامل لأحدث نماذج الذكاء الاصطناعي 2026: GPT-5.3-Codex وClaude Opus 4.6 وGemini 3 Deep Seek وGLM-5
يشهد عام 2026 ثورة حقيقية في مجال نماذج الذكاء الاصطناعي، حيث أطلقت الشركات الرائدة نماذج جديدة تعيد تعريف قدرات الذكاء الاصطناعي في البرمجة وال…
-
دليل شامل: إعداد OpenClaw من الصفر إلى مشروع مدر للدخل (مع بوت Telegram)
في عالم الذكاء الاصطناعي المتسارع، تظهر أدوات تتيح للمطورين والأفراد استغلال قدرات AI لتحسين إنتاجيتهم وأتمتة مهامهم. OpenClaw هو إحدى هذه المنص…
-
دليل بناء RAG في 2026: خطوة بخطوة للمبتدئين
RAG أو Retrieval-Augmented Generation هي تقنية حديثة تجمع بين قوة نماذج اللغة الكبيرة وقواعد البيانات المخصصة. بدلاً من الاعتماد فقط على المعلوم…
-
شرح شامل لـ RAG: من التقسيم والتضمين إلى التقييم
اترك تعليقاً