
في هذا الدليل ستفهم Mixture of Experts (MoE) أو «مزيج الخبراء» كأحد أهم أفكار التوسّع الذكي في نماذج اللغة الكبيرة: كيف تسمح لك ببناء نموذج يملك «عدد معاملات ضخم» لكن بتكلفة حسابية قريبة من نموذج أصغر، عبر تفعيل جزء من الشبكة. للفهم الأعمق، راجع آلية الانتباه (Attention Mechanism) و أفضل نماذج الذكاء الاصطناعي مفتوحة المصدر 2026.ة لكل token بدل تفعيل كل شيء دائماً. إذا كنت تبني LLM أو نظام تدريب/خدمة لنموذج كبير، ففهم MoE اليوم لم يعد رفاهية—بل أداة عملية لتقليل التكلفة وتحسين الأداء عندما تصل النماذج الكثيفة (Dense) إلى عنق الزجاجة.
المحتويات
- ما هي تقنية Mixture of Experts (MoE)؟
- لماذا ظهرت MoE بقوة في نماذج 2026؟
- Dense vs MoE: أين يحدث التوفير فعلاً؟
- مكوّنات طبقة MoE: Experts + Router + Combine
- كيف يعمل الـ Router (Top‑k Routing) خطوة بخطوة؟
- Switch Transformer: لماذا Top‑1 أحياناً أفضل؟
- مشكلة عدم توازن الخبراء (Load Balancing) ولماذا تُفسد التدريب
- تحديات التدريب: الاستقرار، التواصل بين الأجهزة، وذاكرة VRAM
- هل MoE أسرع دائماً؟ قيود الأداء في الواقع
- MoE في Transformers: أين تُوضع الخبراء عادةً؟
- متى تختار MoE بدل نموذج Dense؟ (قرار عملي)
- بدائل MoE عندما لا تناسبك (ولماذا قد تكون أفضل)
- مثال عملي: بناء طبقة MoE مبسطة في PyTorch
- Best Practices من خبرة التنفيذ: 9 نصائح تقلّل الأخطاء
- أسئلة شائعة حول MoE (FAQ)
- الخلاصة والتوصيات
1. ما هي تقنية Mixture of Experts (MoE)؟
MoE هي معمارية (Architecture) تعتمد على الحوسبة الشرطية (Conditional Computation): بدل أن تمر كل token عبر نفس طبقة الـ FFN (كما في Transformer الكثيف)، تقوم طبقة خاصة بتوجيه token إلى خبير واحد أو عدة خبراء (Experts) من مجموعة خبراء، ثم تدمج نتائجهم.
الفكرة الأساسية:
- في النموذج الكثيف Dense: كل الطبقات تُفعّل كل مرة → تكلفة حسابية ثابتة وكبيرة.
- في Sparse MoE: تُفعَّل «شبكة صغيرة» (خبير/خبيران) لكل token → تكلفة أقل لكل token، بينما تبقى القدرة الكلية (عدد المعاملات) ضخمة.
مقال ذو صلة: إذا كنت تبني أنظمة استرجاع ومعرفة، راجع شرح RAG الشامل لتفهم الفرق بين «توسيع المعرفة» و«توسيع المعلمات»: شرح شامل لـ RAG.
2. لماذا ظهرت MoE بقوة في نماذج 2026؟
هل لاحظت أن الحديث عن نماذج «تريليونية» أصبح عادياً؟ المشكلة أن تدريب نموذج Dense بهذا الحجم يعني فاتورة حسابية ضخمة وتعقيداً في النشر.
MoE تعالج هذا التناقض: نريد سعة (Capacity) أعلى بدون مضاعفة FLOPs لكل token.
حسب ورقة A Comprehensive Survey of Mixture-of-Experts (الإصدار v4 بتاريخ 24 يناير 2026)، تُستخدم MoE كحلّ لمشكلتين متكررتين في النماذج الضخمة: استهلاك الموارد وصعوبة ملاءمة البيانات المتغايرة، عبر اختيار خبراء ديناميكياً لكل مدخل.
ولإنشاء صورة أشمل عن «لماذا تتسابق الشركات على التوسّع» (وليس فقط MoE)، يمكنك الرجوع أيضاً إلى دليل أحدث نماذج الذكاء الاصطناعي 2026: دليل النماذج الحديثة.
في تجربتي عند تصميم بنية تدريب، أكبر «مكسب ذهني» من MoE هو أنها تغيّر سؤال التخطيط من:
> كم أستطيع أن أكبر النموذج؟
إلى:
> كيف أجعل التوسّع انتقائياً بحيث أدفع تكلفة الحساب فقط عند الحاجة؟
3. Dense vs MoE: أين يحدث التوفير فعلاً؟
الالتباس الشائع: «MoE يعني نموذج أسرع دائماً». الصحيح: MoE تقلّل الحساب لكل token لأنك لا تستخدم كل الخبراء لكل token، لكنك ما زلت تحمل الكثير من المعاملات في الذاكرة.
مقارنة مختصرة
| البند | Dense Transformer | Sparse MoE Transformer |
|---|---|---|
| المعاملات الكلية | أقل | أعلى (كثير خبراء) |
| FLOPs لكل token | أعلى | أقل (تفعيل k خبراء فقط) |
| VRAM المطلوبة | أقل نسبياً | أعلى (كل الخبراء محمّلة) |
| التعقيد الهندسي | أبسط | أعقد (routing + توازن + تواصل) |
مقال ذو صلة: إذا كان هدفك «خفض التكلفة» وليس فقط «تكبير المعاملات»، ستفيدك مقارنة Fine-tuning vs RAG vs Prompt Engineering لفهم متى تغيّر الاستراتيجية بدل تغيير المعمارية: الدليل الشامل للمقارنة. وإذا كنت تعمل على أنظمة بحث/استرجاع معرفي، فوجود Vector Database قوي قد يكون أهم من أي تغيير معماري في النموذج نفسه: دليل قواعد البيانات المتجهية.
4. مكوّنات طبقة MoE: Experts + Router + Combine
طبقة MoE (في سياق Transformers) تتكون غالباً من:
- Experts: غالباً شبكات FFN/MLP متوازية (E خبراء).
- Router / Gating Network: طبقة صغيرة تعطي توزيعاً أو درجات لكل خبير.
- Routing + Combine:
- تختار Top‑k خبراء لكل token.
- تمرر token للخبراء المختارين.
- تدمج مخرجاتهم (عادةً مجموع موزون).
هذه البنية تظهر بوضوح في أدبيات مثل ورقة Switch Transformers (Fedus et al.) التي تبسّط عملية التوجيه لتقليل التعقيد وعدم الاستقرار.
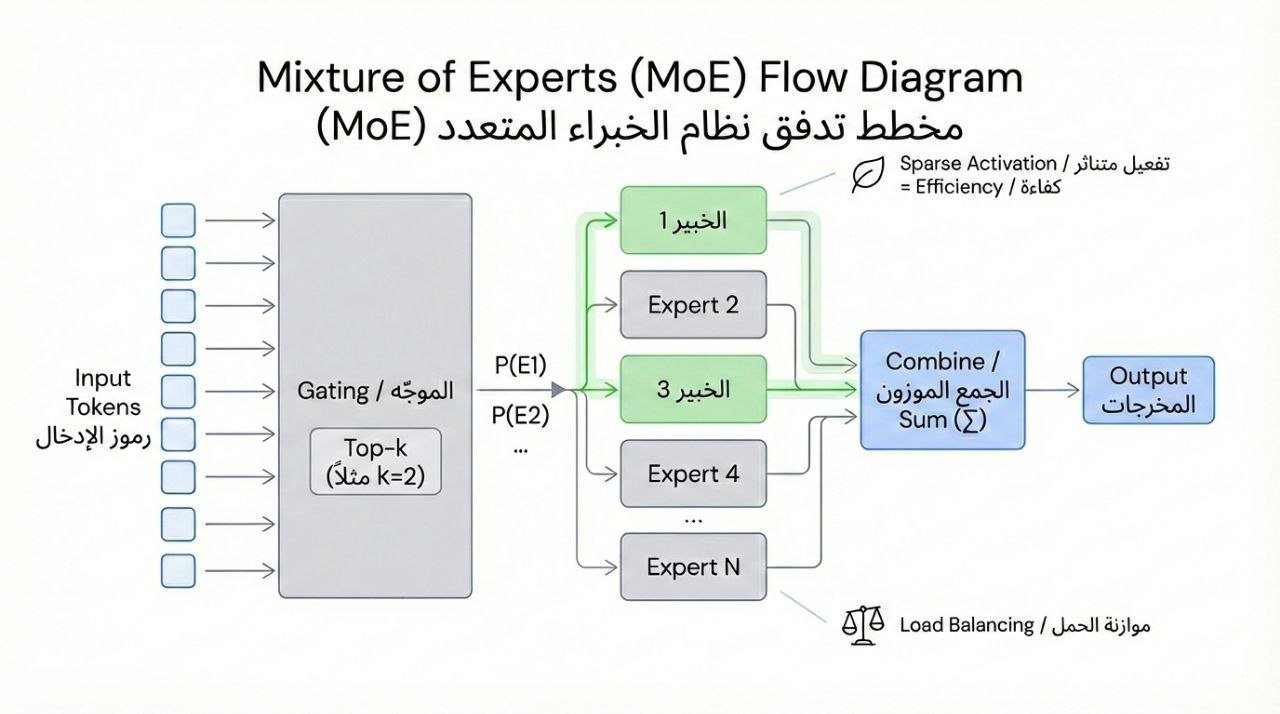
5. كيف يعمل الـ Router (Top‑k Routing) خطوة بخطوة؟
لنأخذ مثالاً عملياً مبسطاً لآلية Top‑k:
- يدخل تمثيل token (vector) إلى الـ Router.
- الـ Router ينتج logits بعدد الخبراء E.
- نحول logits إلى احتمالات (softmax).
- نختار أعلى k خبراء.
- نعيد تطبيع الاحتمالات على الخبراء المختارين (renormalization).
- نحسب مخرجات الخبراء المختارين ونجمّعها.
لماذا إعادة التطبيع مهمّة؟ لأنها تمنع «تصغير» الإشارة عندما نجمع فقط جزءاً من التوزيع.
مثال شبه-كود (فكرة لا أكثر)
x: [batch, d_model]
logits = router(x) # [batch, E]
probs = softmax(logits, dim=-1) # [batch, E]
top-k experts per token
values, indices = topk(probs, k=2) # [batch, 2]
weights = values / values.sum(dim=-1, keepdim=True)
y = sum_i weights_i * expert_i(x)
Tip من خبرة التنفيذ: إذا طبّقت routing بشكل naïve على GPU بدون تجميع/توزيع صحيح، ستخسر الكثير من الأداء في عمليات scatter/gather حتى لو FLOPs أقل.
6. Switch Transformer: لماذا Top‑1 أحياناً أفضل؟
قد تتساءل: لماذا لا نرسل token إلى خبيرين دائماً؟
ورقة Switch Transformers تقترح تبسيطاً: Top‑1 (خبير واحد لكل token) لتقليل:
- تكلفة التواصل All‑to‑All بين الأجهزة.
- التعقيد في الدمج.
- عدم الاستقرار الناتج عن routing.
هذا لا يعني أن Top‑2 «خطأ»، لكنه يعني أن اختيار k هو قرار هندسي وليس «أفضلية مطلقة».
7. مشكلة عدم توازن الخبراء (Load Balancing) ولماذا تُفسد التدريب
أكبر فخّ في MoE: الـ Router قد يتعلم تفضيل خبراء محددين بشدة، فتحدث مشكلتان:
- خبراء يتلقون tokens كثيرة → اختناق (bottleneck) وتباطؤ.
- خبراء يتلقون tokens قليلة → خبراء «جائعون للبيانات» (data starvation) فلا يتعلمون.
لذلك كثير من تطبيقات MoE تضيف خسارة مساعدة (Auxiliary Loss) لضبط التوازن.
حسب مقال Hugging Face عن MoE، يُناقش موضوع load balancing بوضوح مع مفاهيم مثل capacity factor وتكاليف التواصل.
8. تحديات التدريب: الاستقرار، التواصل بين الأجهزة، وذاكرة VRAM
حتى لو كانت MoE رائعة نظرياً، في الواقع ستواجه تحديات عملية:
- Training instability: routing قد يتذبذب مبكراً.
- Communication cost: في التدريب الموزع، tokens تُوجَّه إلى خبراء قد يكونون على أجهزة مختلفة → all‑to‑all مكلف.
- Memory pressure: كل الخبراء موجودون في الذاكرة حتى لو لم تُفعّلهم لكل token.
ورقة GShard تناقش جانباً مهماً: كيف يساعد الشاردينغ (sharding) والأدوات المترجمّة على توسيع نماذج ضخمة مع حساب شرطي.
9. هل MoE أسرع دائماً؟ قيود الأداء في الواقع
لا. إليك 4 أسباب شائعة تجعل MoE أبطأ مما تتوقع:
- Bandwidth/latency بين الأجهزة يقتل مكاسب FLOPs.
- تجزئة غير فعّالة للخبراء تؤدي إلى عدم استغلال كامل للـ GPU.
- Batching أصعب: لأن tokens تتوزع على خبراء مختلفين.
- Serving: عند الاستدلال ستحتاج تحميل كل الخبراء (VRAM)، حتى لو فعّلت اثنين فقط لكل token.
Pitfall شائع: بناء نموذج MoE «عملاق» ثم اكتشاف أن تكلفة VRAM تمنع نشره على البنية التي لديك.
10. MoE في Transformers: أين تُوضع الخبراء عادةً؟
في أغلب التصاميم الحديثة تُستخدم MoE كبديل عن جزء من طبقات Feed‑Forward (FFN) لأن FFN غالباً تمثل جزءاً كبيراً من المعاملات والحساب.
باختصار:
- Attention يبقى غالباً Dense ومشتركاً.
- FFN تصبح خبراء (Experts).
هذا يفسّر لماذا ترى أحياناً نماذج «عدد معاملات ضخم» لكن «حساب قريب من نموذج أصغر».
11. متى تختار MoE بدل نموذج Dense؟ (قرار عملي)
اسأل نفسك هذه الأسئلة قبل أن تختار MoE:
- هل ميزانية التدريب/الحساب هي عنق الزجاجة الأساسي لديك؟
- هل لديك بنية تحتية موزعة تتحمل all‑to‑all بكفاءة؟
- هل لديك فريق قادر على مراقبة التوازن بين الخبراء وضبطه؟
إذا كانت إجاباتك «لا»، فقد يكون نموذج Dense متوسط الحجم + تحسين بيانات/تدريب أفضل.
مقال ذو صلة: لفهم كيف تتحول «الهندسة» إلى نظام عملي على جهازك (أتمتة + وكلاء)، راجع دليل OpenClaw: دليل OpenClaw 2026. ولمن يريد توسيع الفكرة إلى أنظمة متعددة المكونات، هذا دليل متقدم عن وكلاء Multi‑Agent: الدليل الشامل لوكلاء الذكاء الاصطناعي.
12. بدائل MoE عندما لا تناسبك (ولماذا قد تكون أفضل)
MoE ليست الحل الوحيد للتوسّع. بدائل شائعة حسب الهدف:
- RAG: توسّع المعرفة بدون توسّع المعاملات (مفيد عندما المشكلة هي الحقائق/المراجع).
- Fine‑tuning: تخصيص النموذج لمجال معين بدون تغيير المعمارية.
- Distillation: نقل سلوك نموذج كبير إلى أصغر.
- Quantization و KV cache optimizations في الاستدلال.
القاعدة: إذا كانت مشكلتك «المعرفة» فابدأ بـ RAG. إذا كانت مشكلتك «القدرة العامة» أو «التعددية»، عندها فكّر في MoE.
13. مثال عملي: بناء طبقة MoE مبسطة في PyTorch
هذا المثال ليس بديلاً عن مكتبات الإنتاج، لكنه يساعدك تفهم الفكرة بسرعة.
فكرة التنفيذ:
- Router = Linear + softmax
- Experts = قائمة MLPs
- Routing = top‑k
import torch
import torch.nn as nn
class Expert(nn.Module):
def __init__(self, d_model, d_hidden):
super().__init__()
self.net = nn.Sequential(
nn.Linear(d_model, d_hidden),
nn.GELU(),
nn.Linear(d_hidden, d_model),
)
def forward(self, x):
return self.net(x)
class SimpleMoE(nn.Module):
def __init__(self, d_model=768, d_hidden=3072, num_experts=8, k=2):
super().__init__()
self.num_experts = num_experts
self.k = k
self.router = nn.Linear(d_model, num_experts)
self.experts = nn.ModuleList([Expert(d_model, d_hidden) for _ in range(num...
def forward(self, x):
# x: [batch, d_model]
logits = self.router(x)
probs = torch.softmax(logits, dim=-1)
values, indices = torch.topk(probs, k=self.k, dim=-1)
weights = values / (values.sum(dim=-1, keepdim=True) + 1e-9)
# naive combine (للتعليم فقط)
out = torch.zeros_like(x)
for i in range(self.k):
expert_idx = indices[:, i]
w = weights[:, i].unsqueeze(-1)
# تشغيل كل expert على batch كامل هنا غير فعّال، لكنه واضح للتعلم
for e in range(self.num_experts):
mask = (expert_idx == e)
if mask.any():
out[mask] += w[mask] * self.expertse
return out
ملاحظة مهمّة: الكود أعلاه «تعليمي» وليس أمثل للأداء. في الإنتاج ستحتاج routing vectorized وتوزيع الخبراء على الأجهزة أو على مجموعات.
14. Best Practices من خبرة التنفيذ: 9 نصائح تقلّل الأخطاء
- ابدأ بـ k=1 أو k=2 ولا ترفع k قبل قياس التواصل.
- راقب نسبة tokens لكل خبير—إذا رأيت خبيراً يأخذ 60% من المرور، هناك مشكلة.
- استخدم aux loss أو آليات توازن لتقليل الانحياز المبكر في routing.
- لا تفترض أن «عدد معاملات أكبر» يعني جودة أعلى إذا البيانات ضعيفة.
- اختبر MoE على نطاق صغير أولاً (مثلاً 4 خبراء) قبل أن تقفز لـ 64.
- احسب كلفة VRAM عند الاستدلال: كل الخبراء في الذاكرة.
- كن حذراً من الانحراف أثناء fine‑tuning: قد ينهار التوازن إذا لم تضبط الإعدادات.
- لا تقارن MoE بنموذج Dense بنفس «المعاملات الكلية»؛ قارن بـ FLOPs الفعلية لكل token.
- إذا هدفك منتج/خدمة، راقب P95 latency، لأنه أول ما يتضرر عند routing غير متوازن.
مقال ذو صلة: لو مهتم بالجانب التطبيقي في بناء أنظمة تشغيل لوكل/موزعة، راجع دليل بناء وكلاء محلياً بـ LangGraph وDeepSeek R1: دليل عملي.
15. أسئلة شائعة حول MoE (FAQ)
1) هل MoE تجعل النموذج «أذكى» تلقائياً؟
ليس تلقائياً. MoE تعطيك سعة أكبر بكلفة حسابية أقل لكل token، لكن جودة النموذج ما زالت تعتمد على البيانات، التدريب، والاستقرار.
2) ما الفرق بين MoE وEnsemble التقليدي؟
الـ Ensemble يشغّل عدة نماذج/أعضاء غالباً لكل مثال أو يجمع تنبؤاتهم. MoE في نسختها Sparse تشغّل جزءاً من النموذج لكل token عبر Router.
3) لماذا تحتاج MoE إلى VRAM أعلى رغم أنها Sparse؟
لأن «Sparse» هنا تعني sparse في التفعيل وليس في التخزين: الخبراء موجودون في الذاكرة حتى لو لم تستخدمهم جميعاً لكل token.
4) هل MoE مناسبة للتشغيل على جهاز واحد؟
ممكن لأحجام صغيرة/متوسطة. لكن فوائد MoE الكبرى تظهر عندما يصبح الحساب عنق زجاجة ومعك بنية موزعة فعّالة.
5) هل يمكن استخدام MoE مع RAG؟
نعم. RAG يوسّع المعرفة (المحتوى) وممكن أن يكون فوق نموذج Dense أو MoE. كثير من الأنظمة الحديثة تمزج تقنيات متعددة حسب الهدف.
6) ما أهم إشارة خطر أثناء التدريب؟
توازن الخبراء. إذا بدأ routing ينهار نحو خبراء محددين، غالباً ستخسر جودة وتستنزف الأجهزة بلا فائدة.
16. الخلاصة والتوصيات
تقنية Mixture of Experts (MoE) ليست «حيلة» بل إطار هندسي لتكبير السعة دون دفع تكلفة Dense كاملة لكل token. لكنها تأتي بثمن: تعقيد أعلى، تحديات توازن، وتكاليف تواصل وذاكرة.
توصيتي العملية:
- إذا كنت في مرحلة التعلّم أو نموذج صغير → ابدأ Dense + تحسين بيانات/تدريب.
- إذا وصلت إلى سقف FLOPs وتحتاج سعة أكبر → جرّب MoE (k=1 أو k=2) مع مراقبة توازن الخبراء.
- إذا كانت مشكلتك معرفة/مراجع → ابدأ بـ RAG قبل أن تقفز لتغيير المعمارية.
نبذة عن الكاتب
أنا كاتب محتوى تقني مهتم ببناء أنظمة ذكاء اصطناعي عملية (LLMs + RAG + وكلاء)، مع التركيز على تحويل المفاهيم البحثية إلى قرارات هندسية قابلة للتطبيق.
عن الكاتب
علي – خبير تحسين محركات البحث (SEO) ومطور مهتم بالذكاء الاصطناعي. يدير موقع Lira Now المتخصص في أخبار وشروحات AI، ويساعد المواقع العربية على تحسين ترتيبها في نتائج البحث. شغوف باستكشاف أدوات الذكاء الاصطناعي الجديدة وتطبيقها عملياً.
المصادر
- A Comprehensive Survey of Mixture-of-Experts: Algorithms, Theory, and Applications
- The 4 Mixture of Experts Architectures: How to Train 100B Models at 10B Cost
- Mixture of Experts (MoE) From Scratch in PyTorch — Building Sparse Transformers
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
- GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
- Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
- A Review of Sparse Expert Models in Deep Learning
- Mixture of Experts Explained
- Mixtral of experts
- Adaptive Mixture of Local Experts
- Mixture of experts
اترك تعليقاً