Evals للذكاء الاصطناعي: كيف تختبر وكلاء AI وتُحسّن أداءهم؟ دليل مبسط 2026
📅 9 يونيو 2026 | ✍️ علي الرزق | 📂 أنظمة AI
📋 فهرس المحتويات
- 🔹 ما هي الـ Evals تحديداً؟
- 🔹 لماذا الـ Evals مهمة جداً؟
- 🔹 أنواع المقيمين (Graders) — من السريع إلى العميق
- 🔹 التطبيق العملي: بناء وكيل شرائح وتحسينه
- 🔹 الـ QA Loop: حلقة الجودة المزدوجة
- 🔹 النموذج الأذكى: هل يمكنك الاستغناء عن الـ Evals؟
- 🔹 مشكلة المعايرة (Calibration) — لماذا الأرقام ليست كافية
- 🔹 الخاتمة
- ❓ الأسئلة الشائعة
تخيل أنك تشتري سيارة جديدة. هل ستشتريها لمجرد أن شكلها جميل؟ بالطبع لا! ستجرب قيادتها، تختبر المكابح، تتأكد من استهلاك الوقود، وتقرأ تقارير السلامة. هذا بالضبط ما تفعله الـ Evals (التقييمات) مع وكلاء الذكاء الاصطناعي — إنها اختبارات منهجية تقيس أداء الوكيل وتضمن أنه يعمل كما يجب.
في هذا المقال، سنأخذك في رحلة مبسطة لفهم الـ Evals، مستوحاة من محاضرة في Anthropic (الشركة التي صنعت Claude) حول بناء وكيل ذكي يصمم عروض PowerPoint التقديمية (slides) — وكيف تم تحسينه باستخدام التقييمات خطوة بخطوة.
📌 ما هي الـ Evals تحديداً؟
Evals — اختصار لكلمة “Evaluations” أي التقييمات — هي اختبارات منظمة تقيس أداء نظام الذكاء الاصطناعي في مجال أو استخدام معين. تماماً مثل الامتحان المدرسي الذي يقيس مدى فهمك للمادة، الـ Evals تقيس مدى جودة عمل وكيل AI.
تتكون الـ Evals من ثلاثة عناصر رئيسية:
- المهام (Tasks): سيناريوهات محددة نطلب من الوكيل تنفيذها
- التوقعات (Expectations): ما نريد أن ينتجه الوكيل بالضبط
- منطق التصحيح (Grading Logic): طريقة قياس نجاح أو فشل كل مهمة
ببساطة، الـ Evals هي الجسر بين “يبدو أنه يعمل” و “نحن متأكدون أنه يعمل”. فبدون تقييم، أنت تعتمد على المشاعر والانطباعات — وهذا ليس كافياً عندما يكون القرار مهماً.
🎯 لماذا الـ Evals مهمة جداً؟
لنفترض أنك بنيت وكيل AI لمكتب خدمة العملاء. بدونه Evals، ماذا سيحدث؟
- أنت تطير أعمى (Flying Blind): تنتظر شكاوى العملاء لتعرف أن هناك خطأ — وهذا رد فعل متأخر
- إصلاح مشكلة قد يخلق عشر غيرها: تغيير بسيط في التعليمات (prompt) لحل مشكلة قد يكسر مهام أخرى لم تخطر ببالك
- لا تستطيع تمييز الحقيقي من الضوضاء: ليست كل شكوى عميل تعني أن هناك مشكلة حقيقية
- لا توجد طريقة للتحقق من التحسن: كيف تعرف أن التعديل الذي أجريته جعل الوكيل أفضل فعلاً؟
أما مع الـ Evals، فتحصل على:
- وضوح كامل (Clarity): تضطر لتحديد معنى “النجاح” بشكل دقيق
- تحسين مستمر: تختبر تعديلاتك وتعرف أيها الأفضل
- اعتماد نماذج جديدة بثقة: بدلاً من “لنجرب النموذج الجديد ونرى”، لديك أرقام تقارن بين النماذج
- كشف المشاكل قبل الإطلاق: بدلاً من اكتشافها في الإنتاج

⚙️ أنواع المقيمين (Graders) — من السريع إلى العميق
في المحاضرة، شرح المتحدث ثلاثة أنواع من المقيمين، ولكل منها نقاط قوة وضعف:
1. المُقيم البرمجي (Code-based Grader) 🔢
هذا يشبه اختبارات الوحدة (unit tests) في البرمجة — فحص آلي صارم. مثلاً: “هل يوجد ملف PowerPoint في النتيجة؟” أو “كم عدد الكلمات في الشريحة؟”.
- ✅ المزايا: سريع جداً، رخيص، نتيجة ثابتة لا تتغير
- ❌ العيوب: صارم جداً، لا يكتشف الفروق الدقيقة في الجودة
2. المُقيم النموذجي (Model-based Grader/Judge) 🤖
هنا، نستخدم نموذج AI آخر لتقييم الناتج بناءً على معايير محددة. مثلاً: “هل الشريحة منظمة بشكل جيد؟” أو “هل الألوان متناسقة؟”.
وهناك طرق مختلفة:
- التصيف حسب المعايير (Rubric-based): تعطي للنموذج معايير مثلاً “النص يجب أن يكون واضحاً والخط مقروءاً” ويصّنف من 0 إلى 5
- المقارنة الزوجية (Pairwise Comparison): تعرض ناتجين وتطلب من النموذج اختيار الأفضل وشرح السبب
- إجماع الحكام المتعددين (Multi-judge Consensus): ثلاثة نماذج يصّنفون بشكل مستقل، والأغلبية هي الفائزة — مثل لجنة تحكيم
- ✅ المزايا: مرن، يكتشف الفروق الدقيقة، قابل للتوسع
- ❌ العيوب: غير ثابت (غير حتمي)، أغلى، يحتاج معايرة دقيقة
3. المُقيم البشري (Human Grader) 👤
خبير بشري يراجع الناتج ويقيمه. هذا هو الأغلى والأبطأ، لكنه الأعلى جودة.
- ✅ المزايا: أعلى جودة، الأدق في الأمور المعقدة
- ❌ العيوب: مكلف جداً، بطيء، غير مناسب للمهام المتكررة
🔧 التطبيق العملي: بناء وكيل شرائح وتحسينه
الآن، دعنا نرى الـ Evals في العمل. تخيل أنك تريد بناء وكيل AI يصمم عروض PowerPoint تقديمية (مثلاً عن “كيف تطلب زيادة في الراتب”).
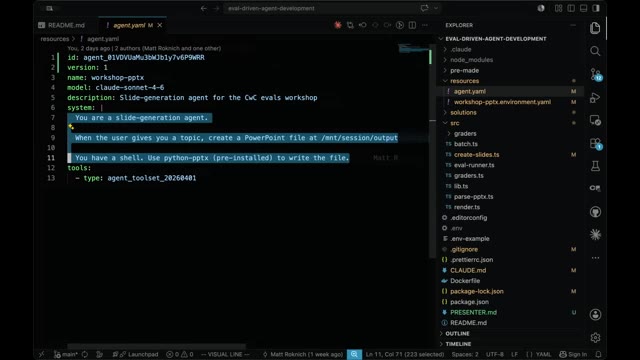
المرحلة 1: الوكيل الأولي — النتائج الأولية
في البداية، أعطوا الوكيل تعليمات بسيطة: “أنت وكيل تصميم شرائح. عندما يعطيك المستخدم موضوعاً، أنشئ ملف PowerPoint”. النتيجة؟ كانت كارثية — نصوص متداخلة، ألوان عشوائية، رموز تعبيرية (emojis) غير مناسبة، وخطوط صغيرة.
المرحلة 2: تحليل النتائج عبر الـ Evals
استخدموا مقيمين برمجيين لقياس أشياء محددة:
- عدد الرموز التعبيرية (emoji count) — 4 رموز
- عدد الشرائح ذات الخط الصغير — 4 شرائح
- الشرائح المزدحمة — 2 شريحة
- الشرائح كثيفة النصوص — تبين أن معظمها يعاني من هذه المشكلة
ثم استخدموا مقيم نموذجي لقياس الجودة من 0 إلى 5 في المجالات: جودة النص، الصورة، التصميم (layout)، والألوان. النتائج كانت بين 2.8 و 4 — مقبولة لكنها ليست ممتازة.
المرحلة 3: تحسين التعليمات (System Prompt) بناءً على الـ Evals
بناءً على نتائج التقييم، أضافوا تعليمات أكثر تحديداً للوكيل:
- حجم الخط المطلوب: عنوان 36pt، نص رئيسي 24pt، تذييل 18pt
- قواعد التصميم: اترك مسافة كافية، النص محاذاة لليسار في الشرائح الغربية
- تجنب علامات AI الواضحة: لا نجوم مزخرفة، لا رموز تعبيرية كثيرة
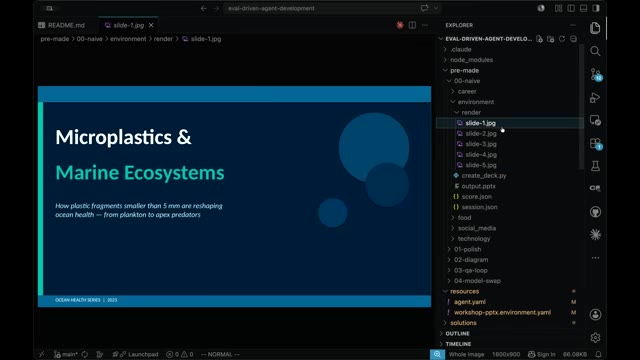
المرحلة 4: التكرار والتطور
بعد التعديل، أصبحت الشرائح أنظف بكثير — ولكن ظهرت مشكلة جديدة: عدد الرموز التعبيرية قفز إلى 20! هذا يدل على أن التقييم بحاجة لمعايرة أيضاً.
وهذا يوضح نقطة مهمة: الـ Evals ليست ثابتة — إنها كائن حي يتطور مع الوقت. تحتاج لمراجعتها وتحديثها باستمرار، لأن ما كان مهماً في البداية قد لا يكون مفيداً لاحقاً.
🔄 الـ QA Loop: حلقة الجودة المزدوجة
واحدة من أقوى التقنيات التي شرحتها المحاضرة هي QA Loop (حلقة ضمان الجودة). الفكرة بسيطة ولكنها عبقريّة:
- وكيل الإنشاء (Creator Agent): الوكيل الأساسي الذي يصمم وينتج
- وكيل النقد (Critic Agent): وكيل ثانٍ مهمته الوحيدة هي إيجاد المشاكل والنقد البنّاء
الوكيل الناقد يقول: “هذا سيء لأن… هذا به خطأ… هذا ليس وفق المعايير…” ثم يعطي هذه الملاحظات للوكيل المُنشئ. الوكيل المُنشئ يأخذها ويحسّن الناتج.
هذه الحلقة تستمر حتى يرضى الطرفان — تماماً مثل محرر صحفي يراجع مقالة كاتبها مراراً حتى تصبح جاهزة للنشر.
🧠 النموذج الأذكى: هل يمكنك الاستغناء عن الـ Evals؟
سؤال مثير: هل يمكن أن يكون النموذج نفسه ذكياً كفاية ليصنع شرائح رائعة دون الحاجة لتقييمات معقدة؟
جربوا هذا: استخدموا نموذج Claude Opus 4.7 (الأقوى) بدلاً من Sonnet 4.6 (المتوسط) مع نفس التعليمات البسيطة الأولية. النتيجة؟
- صفر رموز تعبيرية — النموذج الأكبر “يعرف” أنها غير مناسبة لعرض تقديمي جاد
- نصوص أقل حجماً — لديه معرفة فطرية بأن الشرائح يجب أن تكون مقروءة
- نتائج التقييم: بين 4.2 و 5 من 5!
لكن — وهنا المفاجأة — حتى مع النموذج الأقوى، تحتاج الـ Evals! لماذا؟ لأن الأرقام العالية قد تعني أنك تقيس الشيء الخطأ. في مثالهم، حصلوا على 5/5 في تقييم الصور… مع أنه لم تكن هناك صورة واحدة في العرض! هذا يعني أن المعايير تحتاج تعديلاً.
📊 مشكلة المعايرة (Calibration) — لماذا الأرقام ليست كافية
المحاضرة تطرقت لمشكلة عميقة: كيف تعرف أن رقم “4 من 5” يعني فعلاً شيئاً جيداً؟ الـ LLMs (نماذج اللغة الكبيرة) تعمل بطريقة تلقائية متسلسلة (autoregressive) — إذا قالت “4” أولاً، فستبحث عن أي سبب لتبرير هذا الرقم حتى لو كان الناتج سيئاً.
الحل الذكي: عكس الترتيب! بدلاً من أن تقول النموذج “أعطِ رقماً ثم برر”، قل له: “أولاً، اكتب الإيجابيات والسلبيات، ثم بناءً على هذه القائمة، قرّر الرقم النهائي”. بهذه الطريقة، التبرير يقود الرقم، وليس العكس.
💎 الخاتمة
الـ Evals ليست رفاهية — إنها أساس بناء أي نظام ذكاء اصطناعي موثوق. سواء كنت تبني وكيلاً بسيطاً للرد على الاستفسارات أو نظاماً معقداً متعدد الوكلاء، التقييم هو البوصلة التي تضمن أنك تتحرك في الاتجاه الصحيح.
الخلاصة في ثلاث نقاط:
- ابني تقييماتك الخاصة: المعايير العامة (مثل SWE-bench) لا تكفي لحالتك الخاصة — ابني ما يقيس بالضبط ما تريد
- التقييم كائن حي: الـ Evals تتطور مع نظامك. راجعها باستمرار واسأل: “هل ما زالت تقيس الشيء المهم؟”
- اجمع بين الأنواع: استخدم المقيم البرمجي للفحوص السريعة، والمقيم النموذجي للجودة، والبشري للفحص النهائي
هل جربت استخدام الـ Evals مع مشروع AI خاص بك؟ شاركنا تجربتك في التعليقات! وإذا كان لديك سؤال، اتركه في قسم الأسئلة أدناه. 👇
- مشاهدة المحاضرة الأصلية من Anthropic — Evals for taste: Hill-climbing a slide-generation agent
- SWE-bench — أحد أشهر معايير تقييم قدرات البرمجة للوكلاء
- وثائق Anthropic الرسمية عن الـ Evals
📖 اقرأ أيضاً:
Agentic AI 2026: الدليل الشامل لفهم وبناء الأنظمة المستقلة
— أنظمة الوكلاء المتعددين 2026: من CrewAI إلى MCP
— Tool ولا Skill ولا Sub-agent؟ كيف تفكك وكيل AI
❓ الأسئلة الشائعة
س: هل أحتاج لأن أكون مبرمجاً لاستخدام الـ Evals؟
ليس بالضرورة! بعض أدوات التقييم الجاهزة (مثل واجهات Anthropic أو LangSmith) تسمح لك بإعداد التقييمات بدون برمجة. لكن الفهم العميق يحتاج بعض المعرفة التقنية الأساسية.
س: كم من الوقت يستغرق بناء Evals جيد؟
هذا يعتمد على تعقيد النظام. للتطبيقات البسيطة، يمكنك البدء ببضعة اختبارات برمجية في ساعة واحدة. للأنظمة المعقدة، قد تحتاج أياماً أو أسابيع للمعايرة الدقيقة. الأهم هو أن تبدأ بسيطاً وتطور مع الوقت.
س: ما الفرق بين الـ Evals والـ Benchmarks؟
الـ Benchmarks (المعايير القياسية) مثل SWE-bench هي اختبارات عامة تقارن بين نماذج AI المختلفة. الـ Evals خاصة بك — تقيس أداء وكيلك في حالتك المحددة. الـ Benchmarks كامتحان عالمي، والـ Evals كاختبار شخصي لمادتك الدراسية.
س: ماذا أفعل إذا أعطاني المقيم النموذجي نتائج غير متوقعة؟
أولاً، تأكد من وضوح معايير التقييم. ثانياً، استخدم المقارنة الزوجية (Pairwise Comparison) بدلاً من التصريف المطلق. ثالثاً، أضف أمثلة عملية (good examples vs bad examples) لتعطي النموذج معياراً ملموساً للحكم. إذا استمرت المشكلة، راجع المعايرة أو استخدم إجماع الحكام المتعددين.
س: هل يمكنني استخدام الـ Evals مع أي نوع من وكلاء AI؟
نعم! الـ Evals تنطبق على أي وكيل AI — من كتابة المقالات إلى تحليل البيانات إلى البرمجة. المبدأ واحد: حدد ما تريد قياسه، ابنِ اختباراً له، كرر التحسين. المزيد عن بناء الوكلاء في دليل Agentic AI الشامل.