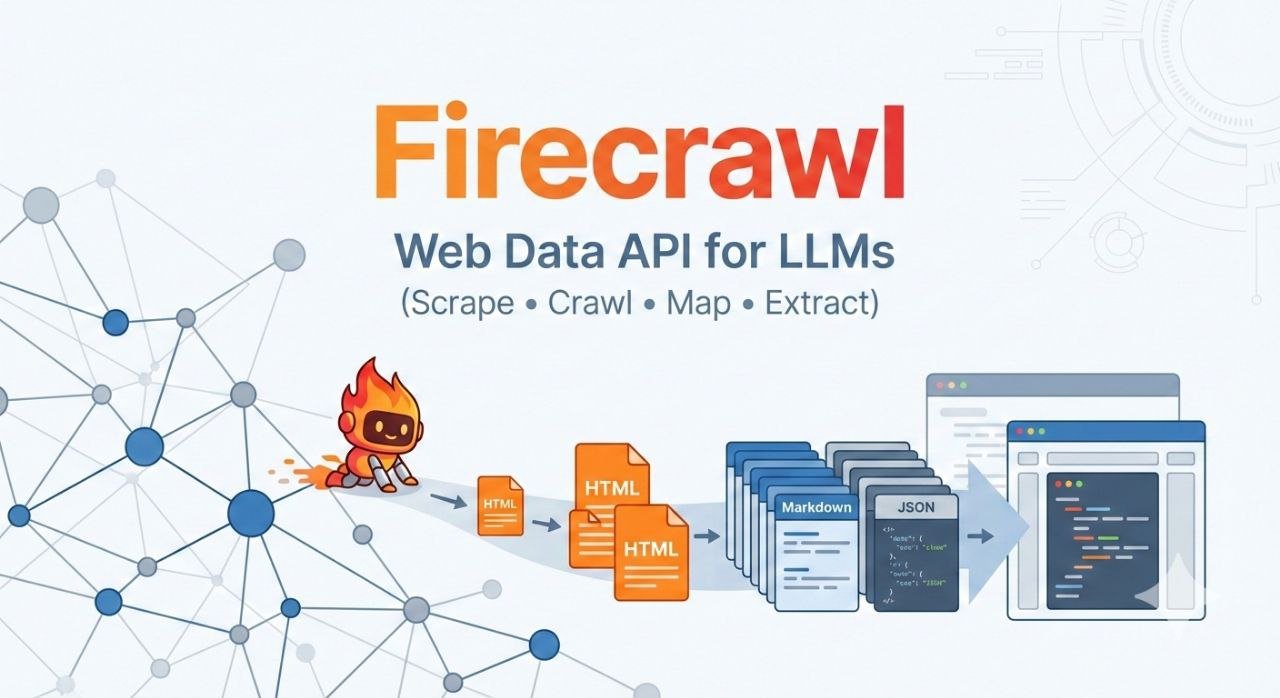
إذا كنت تبني Agent أو نظام RAG أو حتى لوحة تقارير تسحب بيانات من الويب، فأنت تعرف المشكلة: الويب فوضوي (HTML زائد، قوائم، إعلانات، JavaScript، حماية بوت…)، بينما الـ LLM يحتاج نصاً نظيفاً أو JSON منظّم. هنا تأتي Firecrawl كحل “API أولاً” يحوّل الصفحات والمواقع إلى محتوى جاهز للاستخدام.
في هذه المراجعة سأشرح Firecrawl من زاوية عملية: ماذا تقدّم فعلياً؟ كيف تعمل endpoints الأساسية (Scrape/Crawl/Map/Search/Extract)؟ وكيف تقارن ببدائل مثل Apify وCrawl4AI وSkyvern عندما تحتاج قدرات أوسع.
المحتويات
- ما هي Firecrawl وما الذي تميّز به في 2026؟
- لمن تناسب Firecrawl (ومن لا تناسبه)
- الميزات الأساسية: Scrape وCrawl وMap وSearch وExtract
- Browser Sandbox: متى تحتاجه بدلاً من Scrape العادي؟
- جودة البيانات: Markdown مقابل JSON (والفرق على RAG)
- التسعير في 2026: كيف تفهم نظام Credits + Tokens؟
- جدول مقارنة خطط Firecrawl (حسب صفحة التسعير)
- أفضل حالات الاستخدام العملية
- مقارنة Firecrawl مع البدائل (Apify وCrawl4AI وSkyvern)
- كيف تبدأ خلال 15 دقيقة (مثال cURL + Node/Python)
- نصائح لتقليل التكلفة ورفع الدقة
- أسئلة شائعة
- الخلاصة: هل Firecrawl تستحق؟
ما هي Firecrawl وما الذي تميّز به في 2026؟
Firecrawl هي Web Data API هدفها: “تحويل المواقع بالكامل إلى بيانات جاهزة للـ LLM” عبر REST API. بدلاً من كتابة selectors وXPaths (التي تتكسر عند أي تغيير في الواجهة)، تركّز Firecrawl على إخراج:
- Markdown نظيف (مفيد جداً للراغ RAG)
- JSON منظّم عبر schema أو prompt
- خيارات إضافية مثل HTML خام، screenshot، links… حسب استخدامك
الفكرة المهمة هنا: Firecrawl ليست مجرد “سكرابر” تقليدي. هي خدمة مدارة تُخفي وراءها كل أوجاع التشغيل: تشغيل متصفحات Headless، إدارة retries، التعامل مع JS rendering، والالتفاف على “ضجيج” الصفحات.
ومن زاوية السوق، حضورها كان لافتاً لأن كثيراً من فرق الـ AI تريد حلّاً بسيطاً وسريعاً بدون بناء بنية Scraping كاملة. (TechCrunch تحدثت عن Firecrawl كأداة crawling للـ LLMs ضمن موجة الوكلاء والـ agents في 2025، وهو مؤشر على حرارة هذا القطاع).
لمن تناسب Firecrawl (ومن لا تناسبه)
Firecrawl مناسبة لك إذا كنت:
- مطوّر يبني RAG ويحتاج ingestion سريع وموثوق لمحتوى الويب
- فريق منتجات يريد “Web-to-Markdown” بدون هندسة scraping معقدة
- تبني Agent يحتاج جمع سياق من مواقع مختلفة بسرعة عبر API
- تريد endpoints جاهزة (Scrape/Crawl/Map/Search/Extract) بدل تجميع أدوات متعددة
وقد لا تكون مناسبة إذا:
- تحتاج أتمتة متصفح “End-to-End” (تسجيل دخول + 2FA + تعبئة نماذج + تنزيل ملفات) كجزء أساسي من الحل
- تريد سيطرة كاملة على البنية والتكلفة عبر self-hosting production-ready (Firecrawl لديها نسخة مفتوحة المصدر، لكن حسب وصف مشاريع/مراجعات كثيرة: self-hosting ما زال أقل نضجاً مقارنة بالخدمة السحابية)
- تعمل على مواقع عالية الحماية وتحتاج منظومة anti-bot متخصصة جداً (قد تحتاج مزود proxy/anti-bot إضافي)
الميزات الأساسية: Scrape وCrawl وMap وSearch وExtract
من “دليل API” الخاص بـ Firecrawl، هناك 4 endpoints أساسية + Extract كقدرة agentic/structured:
1) Scrape
- تستخدمها عندما تريد صفحة واحدة: مقال، صفحة docs، صفحة منتج، صفحة تسعير.
- تستطيع طلب output مثل markdown أو html أو screenshot…
- الجميل عملياً: وجود خيار Browser Actions قبل السحب (انتظار، ضغط زر، كتابة، scroll…)
2) Crawl
- تستخدمها عندما تريد موقعاً أو جزءاً كبيراً منه.
- مفيدة لتوثيق docs أو مدونة كاملة لإدخالها في RAG.
3) Map
- تُخرج لك “خريطة روابط” (قائمة URLs) بسرعة.
- في مشاريع RAG الكبيرة هذا يوفر وقتاً ضخماً لأنك تبدأ بـ discovery ثم تحدد ما الذي تستحق crawling.
4) Search
- بدل أن تجمع “بحث + سكراب” من أدوات مختلفة، Search هنا يوفّر طبقة بحث ومعها إمكانية جلب محتوى الصفحات.
5) Extract (Structured Data)
- جوهره: استخراج بيانات منظّمة من صفحات الويب باستخدام prompt أو schema.
- عملياً: ممتاز لاستخراج أسعار/مزايا/حقول محددة من صفحات منتجات، أو استخراج قائمة عناصر من صفحة.
Browser Sandbox: متى تحتاجه بدلاً من Scrape العادي؟
ميزة Browser Sandbox (حسب وثائق Firecrawl) تتيح لك فتح جلسة متصفح معزولة مُدارة، ثم تنفيذ أوامر عبر API/CLI/SDK (Node/Python/Bash) باستخدام Playwright أو agent-browser.
متى تكون مفيدة؟
- عندما تكون الصفحة تفاعلية بشكل كبير وتحتاج خطوات متعددة قبل الوصول للمحتوى
- عندما تريد مراقبة live view أثناء اختبار الـ agent
- عندما تحتاج تشغيل كود “داخل المتصفح” وليس مجرد scrape لصفحة ثابتة
إذا كانت احتياجاتك مجرد “اقرأ هذه الصفحة وارجع لي المحتوى”، غالباً Scrape مع Actions يكفي. أما لو تحوّلت العملية إلى سيناريو متصفح معقد، فـ Browser Sandbox يعطيك مرونة أعلى.
جودة البيانات: Markdown مقابل JSON (والفرق على RAG)
في تجربتي مع مشاريع RAG، أكبر مشاكل ingestion ليست “جمع البيانات”، بل تنظيفها بحيث:
- لا تضيع tokens في قائمة تنقّل أو footer
- لا تتكرر نفس المقاطع
- تكون العناوين والهيكلة واضحة
هنا Markdown مفيد جداً: يتم الحفاظ على headings والقوائم والجداول بشكل مفهوم. أما JSON المنظّم فيفيدك عندما تريد: (اقرأ أيضاً: Grok AI: المراجعة الشاملة 2026 – أذكى أداة ذكاء اص…)
- حفظ معلومات محددة في قاعدة بيانات
- بناء مقارنة/فلترة
- تشغيل منطق لاحق بدون parsing نصي
قاعدة عملية:
- إذا هدفك “بحث سياقي + إجابة”: ابدأ بـ Markdown.
- إذا هدفك “لوحة بيانات/تجميع أسعار/كتالوج”: استخدم JSON schema.
التسعير في 2026: كيف تفهم نظام Credits + Tokens؟
من أكثر نقاط الالتباس (وتذكرها مراجعات كثيرة) أن Firecrawl قد تجمع بين:
- Credits لعمليات scrape/crawl/map وغيرها
- Tokens/اشتراك منفصل لبعض قدرات الاستخراج/الـ agentic (بحسب خطة الخدمة وتفاصيل التسعير وقت القراءة)
القاعدة الأفضل: اعتبر أن هناك “تكلفة جمع” + “تكلفة فهم/استخراج” إذا استخدمت ميزات تعتمد على نماذج.
جدول مقارنة خطط Firecrawl (حسب صفحة التسعير)
> ملاحظة: الأرقام تتغير. الجدول التالي مبني على صفحة التسعير الرسمية كما ظهرت وقت إعداد المقال (21 فبراير 2026). راجع الصفحة الرسمية قبل اتخاذ قرار.
| الخطة | السعر (تقريباً/شهرياً عند الفوترة السنوية) | لمن؟ | ملاحظات سريعة |
|---|---|---|---|
| Free | 0$ | تجربة/نماذج أولية | مناسبة لاختبار الدقة والـ output |
| Hobby | ~16$ | مشاريع صغيرة/شخصية | مناسبة لـ MVP وPoC |
| Standard | ~83$ | فريق صغير/منتج ناشئ | أفضل لمن يريد سعة أكبر واستقرار |
| Growth | ~333$ | فرق ومشاريع أكبر | لمن لديه حجم scraping واضح ومستمر |
(مصدر: صفحة التسعير الرسمية لـ Firecrawl).
أفضل حالات الاستخدام العملية
1) إدخال Docs كاملة في RAG
- Map لاكتشاف روابط docs
- Crawl لتجميع الصفحات
- Markdown كصيغة ingestion
مناسب جداً إذا كنت تعمل على مشروع شبيه بموضوع RAG (يمكنك الرجوع لمقالنا الشامل عن RAG: /?p=178).
2) تجميع أسعار ومزايا المنافسين (Competitor Intel)
- Scrape صفحات التسعير
- Extract schema لاستخراج: plan_name, price, limits, features
- تخزين النتائج في DB لعمل مقارنة آلية
3) تغذية Agents بسياق “حديث” من الويب
إذا كنت تبني وكلاء ذكاء اصطناعي، Firecrawl تختصر مرحلة “اجلب محتوى صفحة X ونظفه”. وهذا ينسجم مع فكرة الأنظمة الوكيلة (مقال: /?p=247 و /?p=225).
4) تجهيز Dataset نصي سريع
لمن يريد corpus نصي للتجارب أو حتى fine-tuning/التقييم (انظر أيضاً مقال Fine-tuning vs RAG vs Prompt Engineering: /?p=213).
مقارنة Firecrawl مع البدائل (Apify وCrawl4AI وSkyvern)
لا توجد “أداة واحدة” تربح في كل السيناريوهات. هذه مقارنة عملية مختصرة:
| الأداة | أفضل استخدام | نقاط قوة | نقاط ضعف |
|---|---|---|---|
| Firecrawl | Web-to-Markdown وAPI سريع للـ LLM | سهولة، endpoints جاهزة، Actions، بنية مدارة | التسعير قد يربك (credits + token)، self-hosting أقل نضجاً من السحابة |
| Apify | عمليات scraping + automation واسعة + market of actors | مرونة وبناء workflows | قد تحتاج إعدادات أكثر، وبعض الحالات تتطلب خبرة تشغيل |
| Crawl4AI | لمن يريد حلّاً Python-first ومرن محلياً | مفتوح المصدر، قابل للتخصيص | أنت تدير البنية (تشغيل/Proxy/Scaling)، خبرة تقنية أعلى |
| Skyvern | أتمتة “workflow” بالمتصفح + نماذج رؤية | ممتاز للخطوات المتعددة (forms/auth) | ليس مجرد web-to-markdown، وقد يكون overkill لو هدفك نص فقط |
من منظور “content gaps” في المنافسين: كثير من مراجعات Firecrawl تذكر الميزات العامة، لكن لا تشرح جيداً كيف تختار بين Scrape + Actions وبين Browser Sandbox، ولا تعطي نصائح لتقليل التكلفة عند الزحف على docs كبيرة—ركزتُ هنا على هاتين النقطتين.
كيف تبدأ خلال 15 دقيقة (مثال cURL + Node/Python)
1) Scrape عبر cURL
curl -X POST "https://api.firecrawl.dev/v2/scrape" \
-H "Authorization: Bearer fc-YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"url": "https://example.com",
"formats": ["markdown"] (اقرأ أيضاً: أفضل 5 أدوات ذكاء اصطناعي لإنشاء الفيديو في 2026 (...)
}'
2) Scrape مع Actions (انتظار/ضغط/سكرينشوت)
> الفكرة: عندما لا يظهر المحتوى مباشرة أو تحتاج الضغط على زر “Accept/Load more”.
curl -X POST "https://api.firecrawl.dev/v2/scrape" \
-H "Authorization: Bearer fc-YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"url": "https://example.com",
"formats": ["markdown"],
"actions": [
{"type": "wait", "milliseconds": 1500},
{"type": "scroll", "direction": "down", "amount": 1200}
]
}'
3) Browser Sandbox عندما يتحول الأمر إلى “سيناريو متصفح”
إذا احتجت مرونة أكبر، تستطيع إنشاء session ثم تنفيذ كود (Node/Python/Bash) داخل sandbox (حسب وثائق Browser Sandbox).
نصائح لتقليل التكلفة ورفع الدقة
- ابدأ بـ Map ثم قيّد النطاق: لا تزحف كل شيء.
- استخدم onlyMainContent عندما يكون هدفك نص لتقليل الضجيج.
- فعّل caching/maxAge في الحالات التي لا تحتاج تحديث لحظي (مفيد جداً للـ docs الثابتة).
- قسّم ingestion على دفعات بدل زحف ضخم دفعة واحدة، لتقليل المخاطر ومراقبة الجودة.
- راقب الأخطاء 429/5xx: وثائق Firecrawl تشرح رموز الأخطاء، وهذا مهم لبناء retry/backoff محترم.
ولمن يبني نظاماً كاملاً للوكلاء محلياً، قد يفيدك أيضاً دليلنا التطبيقي عن LangGraph وDeepSeek: /?p=204.
أسئلة شائعة
هل Firecrawl قانونية للاستخدام؟
الأمر يعتمد على ما تجمعه وكيف تستخدمه وشروط المواقع. الأفضل دائماً احترام سياسات المواقع وrobots.txt وتجنب أي استخدام ينتهك الشروط. (اقرأ أيضاً: أفضل 5 أدوات ذكاء اصطناعي لكتابة المحتوى في 2026: …)
هل تدعم الصفحات التي تعتمد على JavaScript؟
نعم، Firecrawl مصممة للتعامل مع dynamic content. وفي الحالات الصعبة يمكنك استخدام Actions أو Browser Sandbox.
ما الفرق بين Scrape وCrawl؟
Scrape صفحة واحدة. Crawl لمجموعة صفحات/موقع كامل.
هل يمكن استخدامها في مشروع عربي (محتوى عربي)؟
نعم. الأهم التأكد من جودة extraction وأن الـ Markdown الناتج يحافظ على الترميز والعناوين.
ما أفضل بديل إذا احتجت تسجيل دخول و2FA؟
غالباً تحتاج أداة تركّز على browser automation/workflows (مثل Skyvern أو أدوات browser automation الأخرى) وليس فقط web-to-markdown.
هل النسخة المفتوحة المصدر كافية؟
مفيدة للتجربة، لكن إذا أردت إنتاجاً بثبات عالي وتحديثات وتحمّل، غالباً ستحتاج النسخة السحابية (أو خبرة تشغيل قوية إذا قررت self-host).
الخلاصة: هل Firecrawl تستحق؟
إذا كان هدفك واضحاً: تحويل صفحات/مواقع إلى Markdown أو JSON جاهز للـ LLM عبر API، فـ Firecrawl من أفضل الخيارات في 2026 لأنها تختصر عليك 80% من “هندسة السحب والتنظيف”.
أنصح بها خصوصاً لـ:
- فرق RAG التي تريد ingestion سريع ومنظّم
- مطوّري agents الذين يحتاجون سياق الويب “كخدمة”
- من يريد PoC سريع قبل الاستثمار في بنية scraping خاصة
ولا أنصح بها كخيار أول إذا كان مشروعك يعتمد على “تصفح معقد + تسجيل دخول + تفاعل كثيف”؛ هنا قد تنجح أكثر أدوات automation متخصصة.
روابط داخلية مقترحة
- دليل الوكلاء الشامل 2026: /?p=247
- وكلاء الذكاء الاصطناعي 2026 (نسخة أخرى): /?p=225
- شرح RAG عملياً: /?p=178
- Fine-tuning vs RAG vs Prompt Engineering: /?p=213
- بناء نظام وكلاء محلياً بـ LangGraph وDeepSeek: /?p=204
- دليل OpenClaw 2026: /?p=165
نبذة عن الكاتب: كاتب مهتم ببناء أنظمة الذكاء الاصطناعي التطبيقية (RAG + Agents) وتحويل الأدوات المعقدة إلى خطوات قابلة للتنفيذ للمطورين ورواد الأعمال.
عن الكاتب
علي – خبير تحسين محركات البحث (SEO) ومطور مهتم بالذكاء الاصطناعي. يدير موقع Lira Now المتخصص في أخبار وشروحات AI، ويساعد المواقع العربية على تحسين ترتيبها في نتائج البحث. شغوف باستكشاف أدوات الذكاء الاصطناعي الجديدة وتطبيقها عملياً.
المصادر
مقالات ذات صلة
-
Grok AI: المراجعة الشاملة 2026 – أذكى أداة ذكاء اصطناعي أم مجرد جدل؟
في عالم الذكاء الاصطناعي المزدحم بالأدوات والنماذج، قليلون هم من يجرؤون على تحدي عمالقة مثل OpenAI وGoogle وAnthropic. لكن Grok AI من شركة xAI ا…
-
أفضل 5 أدوات ذكاء اصطناعي لإنشاء الفيديو في 2026 (مقارنة شاملة)
هل تتخيل إنتاج فيديو سينمائي كامل، بصوت ومؤثرات، بمجرد كتابة سطر واحد؟ في عام 2026، لم يعد هذا خيالاً علمياً. لقد انتقلنا من مقاطع الفيديو المتق…
-
أفضل 5 أدوات ذكاء اصطناعي لكتابة المحتوى في 2026: مقارنة شاملة وعملية
المحتويات مقدمة: لماذا تحتاج أدوات AI للكتابة؟ كيف اخترنا هذه الأدوات الخمس؟ الأداة الأولى: ChatGPT – الأقوى والأشمل الأداة الثانية: Claude – ال…
اترك تعليقاً