توليد النص المعزز بالاسترجاع (RAG) هو أسلوب يربط نماذج اللغة ببيانات حديثة أو خاصة عبر مرحلة استرجاع قبل التوليد، فيمنح الإجابات دقة أعلى ويقلل الهلوسة. الفكرة ببساطة: بدلاً من الاعتماد على ذاكرة النموذج فقط، نزوّده بسياق حيّ من مصادر موثوقة ثم نطلب منه الإجابة. في هذا الدليل العملي، سنشرح RAG بالتفصيل، من التقسيم والتضمين إلى الاسترجاع والتقييم، مع خطوات واضحة وأمثلة مفهومة ومراجع حديثة.
المحتويات
- ما هو RAG ولماذا أصبح أساسياً في 2026؟
- المعمارية الأساسية: من البيانات الخارجية إلى الإجابة
- طرق الاسترجاع: متجهي، نصّي، وهجين
- التقسيم (Chunking): القرار الذي يصنع جودة الإجابة
- إعادة الترتيب (Reranking) ورفع الدقة
- اختيار نموذج التضمين وقاعدة المتجهات
- إدارة تحديث البيانات وجودة المصادر
- تقييم RAG بمقاييس واضحة
- خط أنابيب عملي لبناء RAG خطوة بخطوة
- الحوكمة والأمان والخصوصية
- مقارنة سريعة بين أنماط RAG
- أخطاء شائعة وكيف تتجنبها
- أين يُستخدم RAG عملياً؟
- أدوات ومنصات تساعدك في البناء
- الأسئلة الشائعة
- الخاتمة
- المصادر والمراجع
ما هو RAG ولماذا أصبح أساسياً في 2026؟
مقال مرتبط: دليلك الشامل لـ OpenClaw 2026: مساعد الذكاء الاصطناعي الذي يعمل على أجهزتك ويحقق دخلاً حقيقياً — المحتويات المقدمة ما هو OpenClaw بالضبط؟ آخر تحديثات OpenClaw: الإصدار 2026.2.16 كيفية إعداد OpenCl…
RAG اختصار لـ Retrieval-Augmented Generation، وهو إطار عمل يجمع بين الاسترجاع من مصادر خارجية والتوليد اللغوي. حسب شرح AWS، يعمل RAG بإضافة مكوّن استرجاع يبحث في مصدر خارجي ثم يمرّر النتائج إلى النموذج كجزء من السياق، مما يحسّن دقة الإجابة مقارنة بالاعتماد على المعرفة التدريبية فقط. ويشرح مصدر آخر أن هذه المعمارية تسحب معلومات من مستندات أو قواعد بيانات خاصة ثم تضعها في سياق النموذج لإنتاج ردّ أكثر دقة وأقل هلوسة. هذان المصدران يؤكدان أن الفكرة المركزية لـ RAG هي “استدعاء المعرفة أولاً” ثم “التوليد ثانياً”.
السبب في انتشاره واضح: نماذج اللغة قوية لكنها لا تعرف كل شيء، ولا تتذكر التحديثات الجديدة، كما أن إدخال مستندات ضخمة في السياق مكلف وغير عملي. RAG يقدّم حلاً عملياً: استرجاع قليل لكن دقيق، ثم توليد من سياق محدد. إذا كنت تبني مساعداً داخل شركة، أو محرك بحث ذكي، أو نظام دعم فني يعتمد على وثائق كثيرة، فستحتاج RAG عاجلاً أم آجلاً.
من زاوية أخرى، كثيرون يقارنون بين RAG والتدريب الإضافي (Fine-tuning). التدريب يعيد تشكيل النموذج نفسه، بينما RAG يبقي النموذج كما هو ويضيف معرفة خارجية عند الحاجة. هذا يجعل RAG أسرع في التحديث وأقل تكلفة، خصوصاً عندما تتغير المعلومات كل يوم. لذلك ترى المؤسسات الكبيرة تتجه إلى RAG كخيار أول، ثم تستخدم التدريب فقط عندما يكون السلوك اللغوي نفسه بحاجة تعديل.
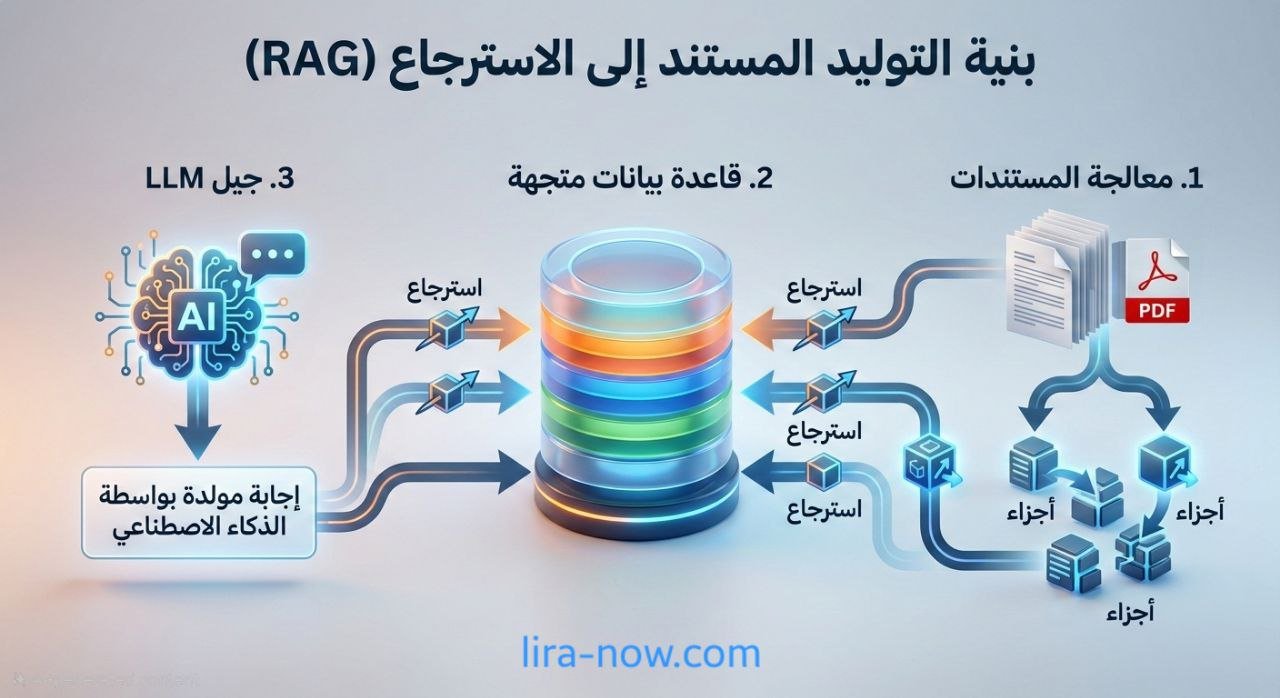
المعمارية الأساسية: من البيانات الخارجية إلى الإجابة
مقال مرتبط: دليل شامل لأحدث نماذج الذكاء الاصطناعي 2026: GPT-5.3-Codex وClaude Opus 4.6 وGemini 3 Pro وGLM-5 — يشهد عام 2026 ثورة حقيقية في مجال نماذج الذكاء الاصطناعي، حيث أطلقت الشركات الرائدة نماذج جديدة تعي…
المعمارية القياسية لـ RAG تتكوّن من سلسلة خطوات متعاقبة. وفقاً لشرح AWS، تبدأ العملية بإنشاء بيانات خارجية (مستندات، قواعد بيانات، أو مستودعات نصية) ثم تحويلها إلى تمثيلات رقمية (Embeddings) وتخزينها في قاعدة متجهات. بعد ذلك، عند وصول السؤال، يتحول إلى تمثيل متجهي ويُستخدم للاسترجاع، ثم تُضاف النتائج إلى نص السؤال ويُرسَل هذا السياق إلى نموذج اللغة ليولّد الإجابة.
مصدر آخر يشرح نفس الفكرة: يتم تقسيم المستندات إلى أجزاء، تحويلها إلى Embeddings، تخزينها في قاعدة متجهات، ثم استخدام الاسترجاع لاستدعاء المقاطع ذات الصلة ودمجها مع السؤال لإنتاج إجابة دقيقة. بهذه الطريقة نحصل على نموذج “مدعوم بالمعرفة” دون إعادة تدريب أو تحديث النموذج نفسه.
المكونات الرئيسية في أبسط صورة
- مصادر البيانات: مستندات، ملفات، قواعد بيانات، مواقع داخلية.
- التقسيم + التضمين: تقطيع النص ثم تحويله إلى متجهات.
- قاعدة متجهات: تخزين embeddings مع الميتاداتا.
- الاسترجاع: البحث عن المقاطع الأقرب للسؤال.
- التعزيز: إدخال المقاطع في سياق النموذج.
- التوليد: إجابة مبنية على السياق المسترجع.
مثال عملي بسيط ذكرته AWS: سؤال موظف عن رصيد الإجازات السنوية. بدلاً من أن “يخمن” النموذج، يتم استرجاع سياسات الإجازات وسجل الموظف ثم تقديم الإجابة بدقة. هذا النوع من السيناريوهات يوضح لماذا RAG أكثر موثوقية في البيئات المؤسسية.
إن كنت مهتماً بتفاصيل النماذج المفتوحة المصدر، قد يفيدك الاطلاع على شرح نموذج DeepSeek R1 لأنه يوضح مفهوم النماذج ذات السياق الكبير وكيف تتأثر بجودة الاسترجاع.
طرق الاسترجاع: متجهي، نصّي، وهجين
الاسترجاع هو قلب RAG. في الأدبيات الحديثة، هناك ثلاث طرق شائعة:
- بحث متجهي (Semantic): يعتمد على تشابه المعنى باستخدام embeddings، وهو ممتاز للأسئلة الصياغية أو المفاهيمية.
- بحث نصّي (Keyword): يعتمد على الكلمات المفتاحية، وهو سريع ودقيق للأسئلة ذات المصطلحات المحددة.
- بحث هجين: يجمع بين الاثنين للحصول على تغطية أوسع.
وفقاً لمصدر Edge AI & Vision Alliance، المزج بين البحث المتجهي والكلمات المفتاحية غالباً ما يكون الأفضل، لأنه يجمع قوة فهم المعنى مع دقة الكلمات الصريحة. هذا الطرح يتطابق مع توصيات عملية عديدة في بناء أنظمة RAG حديثة.
لكن لا تنسَ أن “الهجين” ليس مجرد تشغيل طريقتين معاً؛ بل يحتاج إلى سياسة دمج واضحة (مثل دمج النتائج ثم إعادة الترتيب)، وإلا ستجد أن النظام يعيد مقاطع متكررة أو متضاربة. لذلك من المهم قياس الأداء بعد كل تعديل، وعدم الافتراض أن الإضافة الجديدة ستعني تحسناً تلقائياً.
التقسيم (Chunking): القرار الذي يصنع جودة الإجابة
التقسيم ليس خطوة تقنية ثانوية، بل هو قرار معماري يؤثر مباشرة على جودة الاسترجاع. مصادر متعددة أكدت أن جودة التقسيم تحدد ما إذا كانت المقاطع المسترجعة تحمل معنى كاملاً أم مجرد أجزاء مبتورة تؤدي إلى إجابات مشوشة.
مقال في Dev.to يوضح أن التقسيم الجيد يقلل الهلوسة لأنه يعطي النموذج سياقاً مكتفياً بذاته. ومقال آخر يشرح تجربة قياس فعلية لعدة استراتيجيات تقسيم ويؤكد أن الاختيارات البسيطة أحياناً تتفوق على الخيارات “الذكية” إذا كانت عادلة في ميزانية السياق. هذه النتيجة تعزز فكرة أن التقسيم يحتاج اختباراً تجريبياً، لا وصفة ثابتة.
مبادئ تقسيم عملية
- التوازن بين الحجم والتماسك: جزء كبير جداً يسبب ضجيجاً، جزء صغير جداً يفقد المعنى.
- التداخل (Overlap): ضروري للحفاظ على سياق الجمل المتتابعة.
- التقسيم الدلالي: تقسيم حسب العناوين أو الفقرات قد يكون أفضل من عدد ثابت من الرموز.
مقال Dev.to يشرح أن التقسيم الرديء يؤدي إلى “مقاطع مبتورة” تجعل النموذج يكمل المعلومة من ذاكرته بدلاً من النص، فينتج هلوسة. وفي تجربة أخرى لقياس استراتيجيات مختلفة، تم التأكيد على ضرورة مقارنة الاستراتيجيات بشكل عادل (نفس ميزانية السياق) حتى لا تنحاز النتائج لقطع أكبر حجماً فقط لأنها تحمل سياقاً أطول. هذه الدروس تشير إلى أن التقسيم هو قرار هندسي دقيق، وليس مجرد رقم ثابت.
للمقارنة، يمكنك الاطلاع على تحليل ثورة الذكاء الاصطناعي في فبراير 2026 لمعرفة كيف تتسارع أدوات الاسترجاع في الشركات الكبرى.
إعادة الترتيب (Reranking) ورفع الدقة
حتى بعد الاسترجاع، قد تكون النتائج غير مرتبة بالشكل الأمثل. هنا يأتي دور إعادة الترتيب، وهي خطوة تستخدم نموذجاً أقوى أو أكثر دقة لإعادة ترتيب النتائج المسترجعة بحيث تظهر المقاطع الأكثر ملاءمة أولاً. تقارير حديثة تشير إلى أن إعادة الترتيب تحسن الدقة النهائية وتقلل من إدخال مقاطع غير ذات صلة في السياق.
وفقاً لمصدر Edge AI، إضافة طبقة إعادة ترتيب بعد الاسترجاع يمكن أن ترفع “الدقة” لأنها تزيل الضجيج وتبقي أعلى المقاطع جودة. أما مقالات التقييم الحديثة فتؤكد أن جودة الاسترجاع ترتبط مباشرة بجودة التوليد، وبالتالي فإن أي تحسن في الترتيب ينعكس على الإجابة النهائية.
في الممارسة، تُستخدم أدوات مثل إعادة الترتيب عبر نماذج Transformer أو تطبيق عتبات تشابه (Similarity Thresholding) وإزالة المقاطع القديمة عبر فلترة الميتاداتا. هذه الإجراءات ليست رفاهية؛ بل تمنع النموذج من رؤية سياقات “غير صالحة زمنياً” أو بعيدة عن السؤال.
أين تستخدم إعادة الترتيب؟
- عند وجود قاعدة بيانات كبيرة جداً.
- عند دمج أكثر من مصدر (بحث متجهي + بحث نصي).
- عندما يكون الخطأ مكلفاً (مثلاً في قطاع قانوني أو طبي).
إذا كنت مهتماً بفكرة الوكلاء الذكية التي تنفّذ هذه الطبقات تلقائياً، اقرأ دليل وكلاء الذكاء الاصطناعي 2026.
اختيار نموذج التضمين وقاعدة المتجهات
اختيار نموذج التضمين (Embeddings) هو الخطوة التي تحدد كيف “يفهم” النظام النصوص. إذا كانت البيانات عربية أو ثنائية اللغة، فالأفضل اختبار نموذج يلتقط الفروق الدلالية بدقة. الدرس العملي هنا: النموذج الجيد يقلل العبء على الاسترجاع ويقلل الحاجة للتلاعب بالـ Prompt.
كيف تختار نموذج التضمين؟
- لغة البيانات: إذا كانت عربية بحتة، اختبر نموذجاً يدعم العربية بوضوح.
- حجم البيانات: كلما زاد الحجم، زادت الحاجة لنموذج سريع وكفء.
- الدقة مقابل التكلفة: بعض النماذج أعلى دقة لكنها أبطأ.
اختيار قاعدة المتجهات (Vector DB)
توضح AWS أن Knowledge Bases في Bedrock تدعم عدداً كبيراً من متاجر المتجهات مثل Aurora وOpenSearch Serverless وNeptune Analytics وMongoDB وPinecone وRedis Enterprise، إضافة إلى ربطها بـ Amazon Kendra للبحث الهجين. هذه المرونة تتيح لك اختيار القاعدة المناسبة بحسب حجم البيانات والميزانية ومكان الاستضافة.
إذا كنت تتابع حلول الشركات الكبيرة في هذا المجال، فقد يفيدك الاطلاع على تقارير الأخبار حول تطورات الذكاء الاصطناعي لمعرفة أين تستثمر المؤسسات في البنية التحتية للبحث.
إدارة تحديث البيانات وجودة المصادر
أكبر قوة في RAG هي القدرة على تحديث المعرفة باستمرار. وفقاً لشرح AWS، يمكن تحديث البيانات الخارجية بشكل دوري أو عبر عمليات حية حتى لا تصبح المعلومات قديمة. هذا يعني أن نجاح النظام يعتمد على وجود سياسة تحديث واضحة، مثل مزامنة يومية للوثائق أو تحديث فوري عند تغير السياسات.
ثلاثة مستويات للتحديث
- تحديث فوري: مناسب للأخبار أو الدعم الفني الحي.
- تحديث يومي/أسبوعي: مناسب للوثائق الداخلية المستقرة نسبياً.
- تحديث عند الطلب: عندما يطلب المستخدم معلومة غير موجودة فتُجلب فوراً.
في بيئات تعتمد على الويب، يُستخدم ما يُعرف بـ Web RAG الذي يسحب أدلة من الإنترنت مباشرة ثم يقيّمها ويستخرج أفضل المقاطع قبل الإجابة. هذه الفكرة مذكورة في شرح Skywork الذي يوضح أن الاسترجاع من الويب يحتاج فلترة وترتيباً دقيقين لتجنب الضجيج.
تقييم RAG بمقاييس واضحة
التقييم هو المرحلة التي تحدد إن كان نظامك يعمل فعلاً أم لا. وفقاً لمصادر متخصصة في التقييم، تشمل أهم المقاييس ما يلي:
- Precision@k: نسبة النتائج الصحيحة ضمن أعلى k مقاطع.
- Recall@k: نسبة المعلومات ذات الصلة التي تم استرجاعها.
- NDCG: يقيس جودة ترتيب النتائج (هل الأكثر صلة في الأعلى؟).
مقال Edge AI يشرح هذه المقاييس بشكل عملي مع أمثلة مبسطة، بينما يذكر مصدر آخر متخصص في التقييم أن هذه المقاييس أساسية لأي نظام إنتاجي لأنها تكشف مشكلات الاسترجاع قبل أن تتفاقم في التوليد. الجمع بين المصدرين يؤكد أن التقييم ليس رفاهية، بل ضرورة.
هناك نوعان من التقييم: تقييم غير متصل (Offline) يعتمد على مجموعة أسئلة مُعلّمة، وتقييم متصل (Online) يراقب أداء النظام على أسئلة حقيقية. كثير من الأنظمة تفشل بصمت عندما ينمو حجم البيانات أو تتغير صياغات الأسئلة، لذلك يوصي خبراء التقييم بإنشاء حلقة تغذية راجعة من الإنتاج إلى الاختبار.
خط أنابيب عملي لبناء RAG خطوة بخطوة
لنضع كل ما سبق في خطوات عملية يمكنك تنفيذها:
- حدد مصادر البيانات: مستندات داخلية، قواعد بيانات، وثائق دعم.
- نظّف البيانات: إزالة التكرار والعناوين غير المهمة.
- قسّم المحتوى: جرّب 2-3 إعدادات للتقسيم مع تداخل محدود.
- أنشئ Embeddings: اختر نموذج تضمين مناسب للغة العربية والإنجليزية.
- خزّن في قاعدة متجهات: مع ميتاداتا (تاريخ، مصدر، نوع الوثيقة).
- طبّق استرجاعاً هجينا: متجهي + كلمات مفتاحية.
- أضف إعادة ترتيب: لتحسين ترتيب المقاطع.
- ابنِ Prompt واضحاً: ضع السياق أولاً ثم السؤال.
- قيّم دورياً: استخدم Precision/Recall/NDCG بشكل دوري.
هذه الخطوات تبدو بسيطة، لكن تنفيذها بشكل منضبط يحدد مصير المشروع. كثير من الفرق تقفز مباشرة إلى خطوة التوليد وتنسى تنظيف البيانات أو تحديثها، فيصبح النظام هشّاً. أفضل طريقة هي بناء نسخة أولية صغيرة، ثم توسيعها تدريجياً مع كل دورة تقييم.
مثال مبسط لخط أنابيب RAG
# 1) تحميل البيانات
texts = load_docs("/kb")
# 2) تقسيم
chunks = split(texts, size=400, overlap=50)
# 3) تضمين
vectors = embed(chunks)
# 4) تخزين
vector_db.upsert(vectors, metadata=chunks.meta)
# 5) استرجاع + إعادة ترتيب
candidates = vector_db.search(query, top_k=20)
reranked = rerank(query, candidates)
# 6) بناء السياق ثم التوليد
context = build_context(reranked[:5])
answer = llm.generate(context + "\n" + query)
لمزيد من الأفكار العملية حول بناء أنظمة الوكلاء، ستجد محتوى مفيداً في دليل إعداد OpenClaw من الصفر.
الحوكمة والأمان والخصوصية
أحد أسباب تبنّي RAG في المؤسسات هو الحفاظ على خصوصية البيانات. بدلاً من إدخال الوثائق الحساسة في تدريب النموذج، يسمح RAG باسترجاع أجزاء محددة عند الحاجة ثم تمريرها للسياق فقط. هذا المفهوم مذكور أيضاً في المقالات التي تشرح أن RAG يمكّن الشركات من الاستفادة من قدرات النماذج دون كشف كل بياناتها.
لكن الخصوصية ليست مجرد “مكان تخزين”، بل هي سياسة تشغيل. إذا كان النظام يجيب بناءً على مستندات خاصة، فمن الضروري التأكد من أن الوصول لها مضبوط، وأن هناك سجلاً لمن استرجع ماذا ومتى. هذا يمنع سوء الاستخدام ويزيد ثقة الفرق القانونية والأمنية.
ممارسات أساسية للحوكمة
- التحكم في الوصول: ليس كل موظف بحاجة للوصول لكل مستند.
- التصنيف والوسوم: وسم المستندات حسب الحساسية يساعد على منع التسريب.
- المراجعة الدورية: تحقق من أن الوثائق القديمة لا تزال صالحة.
- التنقيح (Redaction): إزالة بيانات حساسة من المقاطع قبل حقنها في السياق.
الهدف هو أن تكون الإجابة دقيقة وآمنة في آن واحد، لا أن تكون دقيقة فقط.
مقارنة سريعة بين أنماط RAG
فيما يلي مقارنة مختصرة بين أنماط شائعة، مع التركيز على متى تستخدم كل نوع.
| النمط | الوصف المختصر | أفضل استخدام |
|---|---|---|
| RAG القياسي | استرجاع من قاعدة داخلية ثم توليد | مستندات داخلية ثابتة |
| RAG الهجين | دمج البحث المتجهي مع البحث النصّي | أسئلة مختلطة بين المفاهيم والمصطلحات |
| Web RAG | استرجاع من الويب مع فلترة وترتيب | الأخبار والمواضيع المتغيرة بسرعة |
| Multimodal RAG | استرجاع نصوص وصور/وثائق مرئية | الوثائق الغنية بالصور والجداول |
هذه الأنماط ليست متنافسة دائماً؛ يمكن دمجها حسب طبيعة البيانات وحساسية التطبيق.
أخطاء شائعة وكيف تتجنبها
- استخدام تقسيم ثابت دون اختبار: قد يكون مناسباً لحالة واحدة لكنه فاشل لحالات أخرى.
- عدم إضافة ميتاداتا: يجعل تصفية النتائج أصعب.
- عدم قياس الدقة: الاعتماد على الانطباع الشخصي يضلّل فريق التطوير.
- دمج الكثير من المقاطع: سياق طويل جداً يسبب ضياع الإجابة.
- الاعتماد على مصدر واحد: يرفع احتمالات الخطأ إذا كان المصدر قديماً أو ناقصاً.
- غياب سجل أخطاء: عدم توثيق الأسئلة الفاشلة يمنع التحسين المستمر.
هذه الأخطاء تتكرر كثيراً، خصوصاً في المشاريع التي تنطلق بسرعة دون خطة تقييم. أفضل علاج هو بناء قائمة فحص بسيطة لكل إصدار جديد: هل تغيّر شيء في البيانات؟ هل تغيّر الأداء؟ هل ظهرت أسئلة جديدة؟ هذا التفكير الوقائي يقلل الانهيارات المفاجئة.
أين يُستخدم RAG عملياً؟
- الدعم الفني: استرجاع مقاطع من قاعدة المعرفة وربطها بالسؤال.
- الشركات القانونية: البحث في العقود مع تقليل مخاطر الإجابات المضللة.
- التعليم: مساعد دراسي يجيب من مقررات حديثة.
- المؤسسات الصحية: استرجاع بروتوكولات داخلية أو إرشادات محدّثة.
- الموارد البشرية: أسئلة الموظفين حول السياسات والرواتب والإجازات.
- المالية: البحث في السياسات الداخلية والتقارير بسرعة مع تقليل الخطأ.
الجامع بين هذه الحالات أن الإجابة يجب أن تكون دقيقة ومسنودة بمعلومة محددة. وهذا بالضبط ما يقدمه RAG عندما يُنفّذ بشكل صحيح.
ولأن الأخبار تتغير بسرعة، من الجيد متابعة آخر التطورات عبر أخبار الذكاء الاصطناعي الأسبوعية وقمة الذكاء الاصطناعي في الهند 2026 لمعرفة كيف توظّف الشركات RAG عملياً.
أدوات ومنصات تساعدك في البناء
هناك عدد من الأدوات التي تسهّل بناء RAG أو أجزاء منه:
- Amazon Bedrock Knowledge Bases: توفر استيراد بيانات من مصادر متعددة وتحوّلها إلى كتل نصية وتضمينها وتخزينها في قواعد متجهات مع دعم لعدة متاجر متجهية، حسب ما توضحه AWS.
- LangChain: يوفر وحدات لبناء سلسلة كاملة: نماذج، قوالب Prompt، وحدات استرجاع، وذاكرة، حسب شرح AWS.
- أدوات تقييم RAG: منصات متخصصة تقدم مقاييس جاهزة لمراقبة الجودة في الإنتاج، وفقاً لتقارير حديثة في مجال التقييم.
الفكرة هنا ليست اختيار أداة واحدة فقط، بل بناء منظومة متكاملة تتيح لك الاختبار والتحسين بشكل مستمر. كثير من الفرق تبدأ بأداة واحدة ثم تكتشف أنها تحتاج طبقة تقييم أو مراقبة إضافية. لذلك، صمّم المعمارية منذ البداية لتقبل الاستبدال والترقية دون كلفة ضخمة.
إن كنت مهتماً بأدوات بناء الوكلاء بشكل عام، ستجد سياقاً مهماً في دليل وكلاء الذكاء الاصطناعي 2026 لأنه يشرح كيف تتصل طبقات الاسترجاع مع طبقات اتخاذ القرار.
الأسئلة الشائعة
❓ ما الفرق بين RAG وتحديث النموذج بالتدريب؟
التدريب يعني تحديث أوزان النموذج وهو مكلف وبطيء، بينما RAG يضيف معرفة خارجية ديناميكية في زمن الاستدلال، مما يجعله أسرع وأقل تكلفة للتحديث المستمر.
❓ هل يمكن استخدام RAG مع العربية بكفاءة؟
نعم، بشرط اختيار نموذج تضمين جيد يدعم العربية، وضبط التقسيم والتقييم بما يلائم اللغة واتساق النصوص.
❓ ما أفضل حجم للتقسيم؟
لا يوجد رقم ثابت. تجارب عديدة تشير إلى ضرورة اختبار عدة أحجام مع تداخل مناسب قبل اعتماد الإعداد النهائي.
❓ هل البحث الهجين ضروري؟
ليس دائماً، لكنه غالباً يحقق توازناً بين فهم المعنى ودقة المصطلحات، خاصة في البيئات المهنية.
❓ هل إعادة الترتيب تضيف تكلفة كبيرة؟
نعم، لكنها غالباً ترفع الدقة بشكل ملحوظ، ويمكن استخدامها فقط بعد استرجاع أولي واسع لتقليل التكلفة.
❓ ما المقاييس الأهم لتقييم RAG؟
Precision وRecall وNDCG هي الأساس لتقييم الاسترجاع، ويمكن إضافة مقاييس متعلقة بالدقة النهائية للإجابة.
❓ هل يمكن بناء RAG بدون قاعدة متجهات؟
في حالات صغيرة جداً يمكن ذلك، لكن القاعدة المتجهية هي الأكثر كفاءة في التعامل مع النصوص الكبيرة والمتنوعة.
❓ ما أكبر سبب لفشل أنظمة RAG؟
السبب الأكثر شيوعاً هو ضعف الاسترجاع نتيجة تقسيم سيئ أو عدم وجود تقييمات دقيقة.
الخاتمة
RAG لم يعد مجرد تقنية تجريبية، بل أصبح العمود الفقري للعديد من أنظمة الذكاء الاصطناعي في 2026. نجاحه يعتمد على جودة الاسترجاع والتقسيم والتقييم، وليس على قوة النموذج فقط. إذا كنت تبني مساعداً ذكياً أو نظاماً معرفياً، فابدأ بخط أنابيب واضح، وراقب المقاييس باستمرار، وتذكّر أن التحسين عملية مستمرة لا تتوقف.
تذكّر أيضاً أن بناء RAG ليس مشروعاً لمرة واحدة. ستجد أسئلة جديدة، وتغيرات في البيانات، واحتياجات جديدة من المستخدمين. كل دورة تحسين ينبغي أن تضيف توثيقاً إضافياً: ما الذي تغير؟ ما المقياس الذي تحسن؟ وما المشكلة التي ما زالت قائمة؟ بهذه الطريقة تبني نظاماً ينضج مع الزمن بدلاً من أن يتدهور تدريجياً.
نصيحتي النهائية: ركّز على جودة البيانات والاسترجاع قبل التفكير في “ترقيع” الإجابات عبر الـ Prompt. هذه هي الطريقة التي تصنع نظاماً موثوقاً حقاً.
عن الكاتب
علي – خبير تحسين محركات البحث (SEO) ومطور مهتم بالذكاء الاصطناعي. يدير موقع Lira Now المتخصص في أخبار وشروحات AI، ويساعد المواقع العربية على تحسين ترتيبها في نتائج البحث. شغوف باستكشاف أدوات الذكاء الاصطناعي الجديدة وتطبيقها عملياً.
مقالات ذات صلة
-
دليلك الشامل لـ OpenClaw 2026: مساعد الذكاء الاصطناعي الذي يعمل على أجهزتك ويحقق دخلاً حقيقياً
المحتويات المقدمة ما هو OpenClaw بالضبط؟ آخر تحديثات OpenClaw: الإصدار 2026.2.16 كيفية إعداد OpenClaw: دليل شامل للمبتدئين Skills: قلب قوة OpenC…
-
دليل شامل لأحدث نماذج الذكاء الاصطناعي 2026: GPT-5.3-Codex وClaude Opus 4.6 وGemini 3 Pro وGLM-5
يشهد عام 2026 ثورة حقيقية في مجال نماذج الذكاء الاصطناعي، حيث أطلقت الشركات الرائدة نماذج جديدة تعيد تعريف قدرات الذكاء الاصطناعي في البرمجة وال…
-
دليل شامل: إعداد OpenClaw من الصفر إلى مشروع مدر للدخل (مع بوت Telegram)
في عالم الذكاء الاصطناعي المتسارع، تظهر أدوات تتيح للمطورين والأفراد استغلال قدرات AI لتحسين إنتاجيتهم وأتمتة مهامهم. OpenClaw هو إحدى هذه المنص…
-
دليل بناء RAG في 2026: خطوة بخطوة للمبتدئين
RAG أو Retrieval-Augmented Generation هي تقنية حديثة تجمع بين قوة نماذج اللغة الكبيرة وقواعد البيانات المخصصة. بدلاً من الاعتماد فقط على المعلوم…
-
شرح GPT-5.3-Codex: نموذج OpenAI الجديد للبرمجة الذكية (2026)
📚 جدول المحتويات 1. مقدمة: ثورة جديدة في البرمجة بالذكاء الاصطناعي 2. ما هو GPT-5.3-Codex؟ 3. التطور التاريخي: من Codex الأصلي إلى 5.3 4. المميز…
اترك تعليقاً