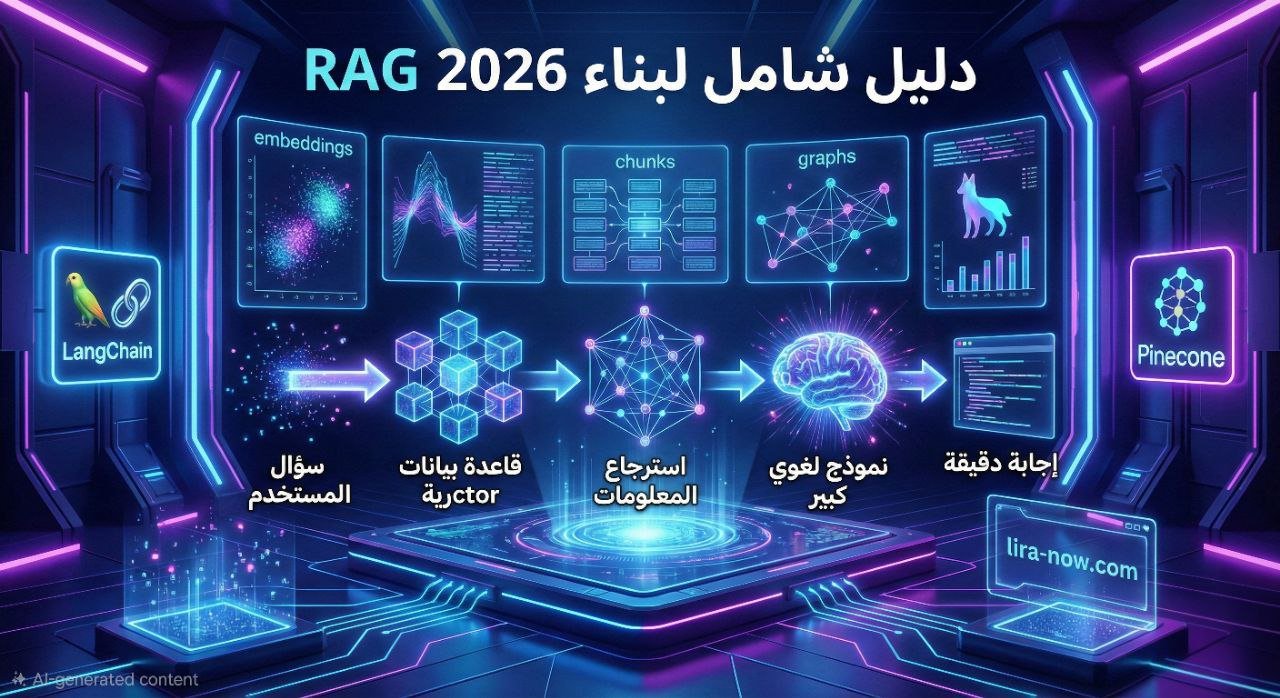
RAG أو Retrieval-Augmented Generation هي تقنية حديثة تجمع بين قوة نماذج اللغة الكبيرة وقواعد البيانات المخصصة. بدلاً من الاعتماد فقط على المعلومات التي تدرب عليها النموذج، يستطيع نظام RAG البحث في مستنداتك الخاصة وتقديم إجابات دقيقة مبنية على بياناتك الفعلية.
في هذا الدليل الشامل، سنستعرض كل ما تحتاج معرفته لبناء نظام RAG احترافي من الصفر، مع أمثلة عملية وحلول للمشاكل الشائعة.
📚 جدول المحتويات
ما هو RAG؟
RAG (Retrieval-Augmented Generation) تعني “التوليد المعزز بالاسترجاع”. هو نهج يجمع بين نموذج لغة كبير (LLM) مثل GPT-4 مع قاعدة بيانات للمعلومات الخاصة بك.
عندما يسأل المستخدم سؤالاً:
1. يبحث النظام في قاعدة البيانات عن المعلومات ذات الصلة
2. يرسل هذه المعلومات مع السؤال إلى نموذج اللغة
3. يولّد النموذج إجابة مبنية على المعلومات المسترجعة
النتيجة: إجابات دقيقة مبنية على بياناتك الحقيقية، وليس فقط على معرفة النموذج العامة.
لماذا تحتاج RAG؟
هناك عدة أسباب تجعل RAG ضرورياً للتطبيقات الحديثة:
معلومات محدثة
نماذج اللغة تتدرب على بيانات قديمة. RAG يتيح لك استخدام أحدث المعلومات من مستنداتك.
دقة أعلى
بدلاً من “اختراع” معلومات، يعتمد النظام على مصادر موثوقة من قاعدة بياناتك.
خصوصية البيانات
بياناتك تبقى على سيرفرك الخاص، لا ترسل لتدريب نماذج خارجية.
توفير التكاليف
تدريب نموذج كامل على بياناتك مكلف جداً. RAG يعطيك نتائج مشابهة بتكلفة أقل بكثير.
قابلية التحديث
يمكنك تحديث قاعدة البيانات في أي وقت بدون إعادة تدريب النموذج.
كيف يعمل RAG؟
دعنا نفهم الآلية الداخلية لنظام RAG:
المرحلة الأولى: تحضير البيانات (Indexing)
1. جمع المستندات
تجمع جميع الملفات التي تريد أن يستخدمها النظام: PDF، Word، صفحات ويب، قواعد بيانات، إلخ.
2. تقسيم النصوص (Chunking)
المستندات الكبيرة تُقسّم إلى أجزاء صغيرة (عادة 500-1000 حرف لكل جزء). هذا يسهّل البحث ويحسّن الدقة.
3. تحويل إلى Embeddings
كل جزء نصي يتحول إلى “embedding” – مجموعة أرقام (vector) تمثل معناه. النصوص المتشابهة في المعنى لها embeddings متقاربة.
4. تخزين في Vector Database
تُخزن هذه الـ embeddings في قاعدة بيانات متخصصة تسمح بالبحث السريع عن التشابه الدلالي.
المرحلة الثانية: الاستعلام (Querying)
عندما يطرح المستخدم سؤالاً:
1. تحويل السؤال إلى Embedding
السؤال يتحول إلى embedding بنفس طريقة تحويل النصوص.
2. البحث في قاعدة البيانات
تبحث قاعدة البيانات عن أقرب embeddings للسؤال (أي النصوص الأكثر صلة).
3. استرجاع النصوص الأكثر صلة
عادة يُسترجع أهم 3-5 أجزاء نصية.
4. إرسال للنموذج
السؤال الأصلي + النصوص المسترجعة يُرسلان معاً لنموذج اللغة.
5. توليد الإجابة
النموذج يقرأ النصوص المسترجعة ويُنشئ إجابة دقيقة مبنية عليها.
الأدوات والمكتبات الأساسية
لبناء نظام RAG، تحتاج إلى ثلاثة مكونات رئيسية:
1. مكتبات بناء RAG
| المكتبة | المميزات | الأفضل لـ |
|---|---|---|
| LangChain | شاملة، مجتمع كبير، سهلة التعلم | المشاريع العامة والمبتدئين |
| LlamaIndex | متخصصة في ربط البيانات، أداء عالي | التطبيقات التي تحتاج بيانات كبيرة |
| Haystack | مرنة، دعم متعدد اللغات | البحث الذكي والتطبيقات متعددة اللغات |
2. قواعد بيانات Vector Databases
| قاعدة البيانات | النوع | الأفضل لـ |
|---|---|---|
| Chroma | مفتوحة المصدر، محلية | التطوير والمشاريع الصغيرة |
| Pinecone | سحابية، مدفوعة | الإنتاج والتطبيقات الكبيرة |
| Weaviate | مفتوحة المصدر + سحابية | المشاريع المتوسطة والكبيرة |
| Qdrant | مفتوحة المصدر، سريعة | الأداء العالي |
3. نماذج Embeddings
OpenAI Embeddings (text-embedding-3-small/large)
الأكثر شهرة، دقة عالية، دعم جيد للغة العربية. التكلفة: $0.02 لكل مليون token.
Cohere Embeddings
جودة ممتازة مع خطة مجانية. دعم متعدد اللغات.
Sentence Transformers (مجاني)
مفتوح المصدر، يعمل محلياً، دعم اللغة العربية يعتمد على النموذج المستخدم.
بناء نظام RAG خطوة بخطوة
دعنا نبني نظام RAG كامل باستخدام Python و LangChain:
الخطوة 1: تثبيت المكتبات
pip install langchain chromadb openai pypdf python-dotenv
الخطوة 2: إعداد API Key
أنشئ ملف .env وضع فيه مفتاح OpenAI:
OPENAI_API_KEY=your-api-key-here
الخطوة 3: الكود الكامل
from langchain.document_loaders import PyPDFLoader, DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
from dotenv import load_dotenv
import os
# تحميل المفاتيح
load_dotenv()
# 1. تحميل المستندات
print("📄 تحميل المستندات...")
loader = DirectoryLoader('documents/', glob="**/*.pdf", loader_cls=PyPDFLoader)
documents = loader.load()
print(f"✅ تم تحميل {len(documents)} مستند")
# 2. تقسيم النصوص
print("✂️ تقسيم النصوص...")
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
texts = text_splitter.split_documents(documents)
print(f"✅ تم إنشاء {len(texts)} جزء نصي")
# 3. إنشاء Embeddings وقاعدة البيانات
print("🧠 إنشاء Embeddings...")
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(
documents=texts,
embedding=embeddings,
persist_directory="./chroma_db"
)
print("✅ تم إنشاء قاعدة البيانات")
# 4. إنشاء نموذج الدردشة
llm = ChatOpenAI(
temperature=0,
model="gpt-4"
)
# 5. إنشاء سلسلة RAG
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever(
search_kwargs={"k": 3}
),
return_source_documents=True
)
# 6. استخدام النظام
def ask_question(question):
print(f"\n❓ السؤال: {question}")
result = qa_chain({"query": question})
print(f"\n💬 الإجابة: {result['result']}")
print("\n📚 المصادر:")
for i, doc in enumerate(result['source_documents'], 1):
print(f"{i}. {doc.metadata.get('source', 'غير معروف')}")
return result
# مثال على الاستخدام
if __name__ == "__main__":
# أمثلة أسئلة
ask_question("ما هو RAG؟")
ask_question("كيف أبني نظام RAG؟")
ask_question("ما هي أفضل قاعدة بيانات لـ RAG؟")
أمثلة عملية بالكود
مثال 1: RAG بسيط للإجابة على أسئلة من PDF
from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# تحميل PDF واحد
loader = PyPDFLoader("document.pdf")
pages = loader.load_and_split()
# إنشاء قاعدة بيانات
vectorstore = Chroma.from_documents(pages, OpenAIEmbeddings())
# إنشاء سلسلة Q&A
qa = RetrievalQA.from_chain_type(
llm=ChatOpenAI(),
retriever=vectorstore.as_retriever()
)
# طرح سؤال
answer = qa.run("ما هي النقاط الرئيسية في المستند؟")
print(answer)
مثال 2: RAG مع ذاكرة المحادثة
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain
# إنشاء ذاكرة للمحادثة
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
# إنشاء سلسلة محادثة
conversation = ConversationalRetrievalChain.from_llm(
llm=ChatOpenAI(),
retriever=vectorstore.as_retriever(),
memory=memory
)
# محادثة متعددة الأدوار
print(conversation({"question": "ما هو RAG؟"})['answer'])
print(conversation({"question": "كيف يختلف عن البحث العادي؟"})['answer'])
print(conversation({"question": "أعطني مثالاً عملياً"})['answer'])
مثال 3: RAG مع تخصيص Prompt
from langchain.prompts import PromptTemplate
# تخصيص الـ prompt
template = """
أنت مساعد ذكي متخصص في الإجابة على الأسئلة بناءً على السياق المعطى.
السياق: {context}
السؤال: {question}
قدم إجابة دقيقة ومفصلة بناءً على السياق فقط. إذا لم تجد الإجابة في السياق، قل "لا أملك معلومات كافية للإجابة على هذا السؤال".
الإجابة:
"""
prompt = PromptTemplate(
template=template,
input_variables=["context", "question"]
)
# استخدام الـ prompt المخصص
qa_with_custom_prompt = RetrievalQA.from_chain_type(
llm=ChatOpenAI(),
retriever=vectorstore.as_retriever(),
chain_type_kwargs={"prompt": prompt}
)
نصائح مهمة لتحسين الأداء
1. اختيار حجم القطع (Chunk Size)
قطع صغيرة (200-500 حرف):
– مزايا: دقة أعلى، استهلاك أقل للـ tokens
– عيوب: قد تفقد السياق
قطع كبيرة (1000-2000 حرف):
– مزايا: سياق أفضل، فهم أعمق
– عيوب: استهلاك أكبر للـ tokens، دقة أقل قليلاً
نصيحة: ابدأ بـ 1000 حرف مع تداخل 200 حرف، ثم جرّب قيم مختلفة حسب نوع بياناتك.
2. عدد النتائج المسترجعة (k)
k=3: مناسب لمعظم الحالات، توازن بين الدقة والتكلفة
k=5: للبيانات المعقدة التي تحتاج سياق أكبر
k=1-2: للإجابات السريعة على أسئلة بسيطة
3. تحسين الأداء والتكاليف
استخدم Cache:
from langchain.cache import InMemoryCache from langchain.globals import set_llm_cache set_llm_cache(InMemoryCache())
اختر النموذج المناسب:
– GPT-4: للإجابات المعقدة التي تحتاج تحليل عميق
– GPT-3.5-turbo: للإجابات البسيطة، أرخص بكثير
4. تنظيف البيانات قبل الفهرسة
import re
def clean_text(text):
# إزالة رموز غير ضرورية
text = re.sub(r'[^\w\s\u0600-\u06FF]', ' ', text)
# إزالة مسافات زائدة
text = re.sub(r'\s+', ' ', text)
return text.strip()
# تطبيق على المستندات
cleaned_docs = [clean_text(doc.page_content) for doc in documents]
مشاكل شائعة وحلولها
المشكلة 1: إجابات غير دقيقة
الأسباب المحتملة:
– حجم القطع غير مناسب
– عدد نتائج قليل جداً (k صغير)
– نموذج Embeddings ضعيف
– البيانات غير منظمة
الحلول:
– جرّب أحجام قطع مختلفة (500, 1000, 1500)
– زد قيمة k إلى 5 أو أكثر
– استخدم OpenAI embeddings بدلاً من النماذج المجانية
– نظّف البيانات وأزل المحتوى غير المفيد
المشكلة 2: بطء الاستجابة
الأسباب المحتملة:
– قاعدة بيانات كبيرة جداً
– استخدام GPT-4 للإجابات البسيطة
– عدم استخدام Cache
الحلول:
– استخدم قاعدة بيانات أسرع مثل Pinecone
– استخدم GPT-3.5 للأسئلة البسيطة
– فعّل الـ Cache
– قلل قيمة k
المشكلة 3: تكاليف عالية
الحلول:
– استخدم GPT-3.5-turbo بدلاً من GPT-4
– استخدم Sentence Transformers (مجاني) للـ embeddings
– فعّل الـ Cache للأسئلة المتكررة
– قلل حجم القطع لتقليل tokens المرسلة
المشكلة 4: ضعف دعم اللغة العربية
الحلول:
– استخدم GPT-4 (دعم عربي ممتاز)
– استخدم OpenAI embeddings (دعم جيد للعربية)
– زد حجم القطع للعربية (1500 بدلاً من 1000)
– جرّب Cohere embeddings (دعم متعدد اللغات)
أسئلة شائعة
ما الفرق بين RAG و Fine-tuning؟
RAG: يبحث في بياناتك عند كل سؤال. مرن، سهل التحديث، لا يحتاج إعادة تدريب.
Fine-tuning: يُعيد تدريب النموذج على بياناتك. أسرع عند الاستخدام، لكن مكلف ويحتاج إعادة تدريب لأي تحديث.
متى تستخدم كل واحد:
– RAG: للبيانات المتغيرة باستمرار، والميزانيات المحدودة
– Fine-tuning: للمهام المتخصصة جداً التي تحتاج أسلوب أو نبرة معينة
هل يمكن استخدام RAG بدون OpenAI؟
نعم! يمكنك استخدام:
– نماذج مفتوحة المصدر: LLaMA, Mistral, Falcon
– Embeddings مجانية: Sentence Transformers
– قاعدة بيانات محلية: Chroma, Qdrant
هذا يعطيك نظام RAG مجاني 100%، لكن الجودة قد تكون أقل من OpenAI.
كم تكلفة تشغيل نظام RAG؟
مثال واقعي:
– 1000 سؤال/يوم
– مستندات بحجم 100 صفحة
– استخدام GPT-3.5 + OpenAI embeddings
التكلفة الشهرية: $15-30
تكلفة Embeddings: مرة واحدة عند الفهرسة (~$1 لكل 100 صفحة)
تكلفة الاستعلامات: $0.002 لكل سؤال تقريباً
هل RAG مناسب للمشاريع الصغيرة؟
نعم تماماً! RAG مثالي للمشاريع الصغيرة لأنه:
– لا يحتاج استثمار ضخم مقدماً
– يمكن البدء بنسخة مجانية (Chroma + Sentence Transformers)
– سهل التطوير والصيانة
– يتوسع معك عند النمو
كيف أحمي بيانات المستخدمين في RAG؟
أفضل الممارسات:
– استخدم نماذج محلية (self-hosted) للبيانات الحساسة
– شفّر قاعدة البيانات
– استخدم خطط enterprise من OpenAI (لا تُستخدم البيانات للتدريب)
– طبّق فصل بيانات المستخدمين (multi-tenancy)
عن الكاتب
علي – خبير تحسين محركات البحث (SEO) ومطور مهتم بالذكاء الاصطناعي. يدير موقع Lira Now المتخصص في أخبار وشروحات AI، ويساعد المواقع العربية على تحسين ترتيبها في نتائج البحث. شغوف باستكشاف أدوات الذكاء الاصطناعي الجديدة وتطبيقها عملياً.
الخاتمة
بناء نظام RAG في 2026 أصبح أسهل من أي وقت مضى. الأدوات ناضجة، التكاليف معقولة، والنتائج مبهرة.
ملخص الخطوات:
1. اختر أدواتك (LangChain + Chroma + OpenAI للبداية)
2. جهّز بياناتك ونظفها
3. قسّم النصوص إلى أجزاء مناسبة (1000 حرف)
4. أنشئ embeddings وخزّنها
5. اربط مع نموذج اللغة
6. جرّب وحسّن الأداء
الخطوة التالية:
لا تنتظر! ابدأ بمشروع صغير اليوم. جرّب الكود الموجود في هذا المقال، وطوّره حسب احتياجاتك.
RAG ليس مجرد تقنية—هو مفتاح لبناء تطبيقات ذكاء اصطناعي عملية تحل مشاكل حقيقية.
مصادر إضافية للتعلم:
– LangChain Documentation
– Pinecone RAG Guide
– OpenAI Embeddings Guide
هل أنت مستعد لبناء نظام RAG الخاص بك؟ ابدأ الآن!
اترك تعليقاً